作者 formath 2023-06-30
模型召回如何打压热门内容
背景
理论上的召回模型,是根据概率分
这里的
概率分
离线训练时,正样本往往是用户历史正反馈数据,比如点击、转化、收藏、转发。而
- Softmax近似方法(一) - Noise Contrastive Estimation理论详解
- Softmax近似方法(二) - Sampled Softmax理论详解
- Softmax近似方法(三) - NCE、NEG、Sampled Softmax对比
为了离线训练时的样本空间尽量和线上对齐,负采样要保证覆盖到全部item。另外,正样本中热门item的占比往往非常大,为了降低整体训练loss,最终得到的用户向量和热门item的向量往往分数更高,这样就导致线上召回时top K也被热门item占领,和业务目标偏离。
热门item的定义
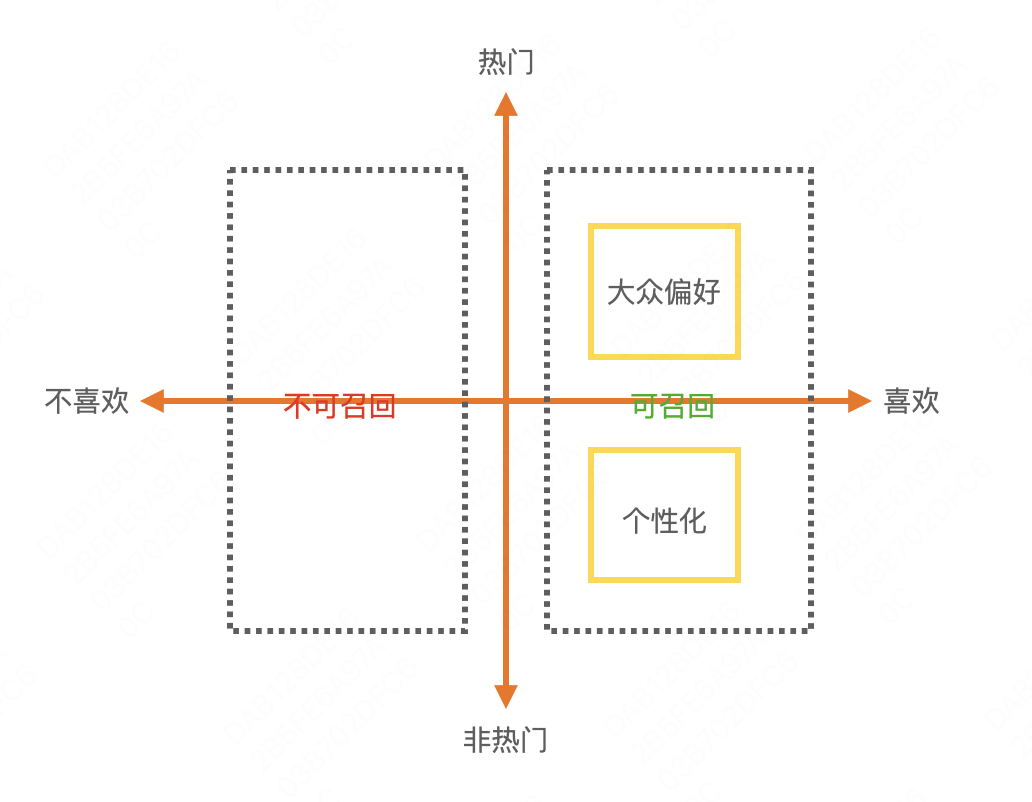
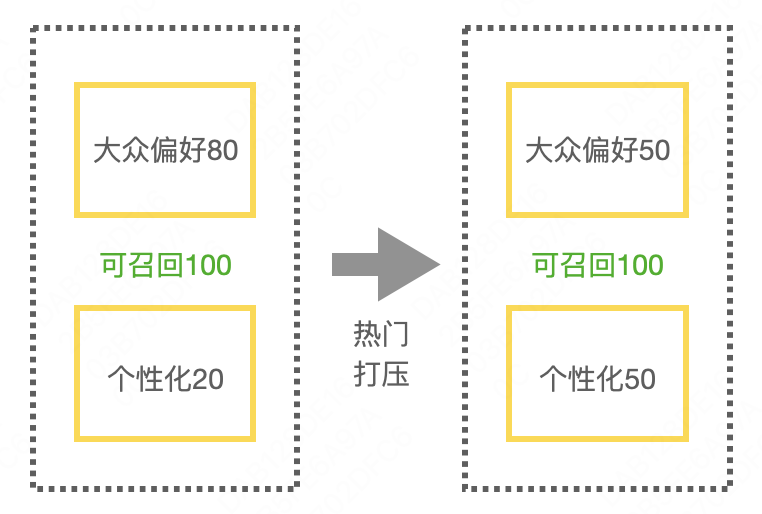
那么,平衡又怎么定义好坏呢?在不打压热门item的时候,热门item占比80%,个性化item只占20%。打压之后,让热门item占比20%,个性化item占比80%算好吗,甚至个性化占100%可行吗?笔者认为可以。原因是召回往往是多通路召回,模型召回只是其中一路。热门item通过简单的统计即可实现召回,无需借助模型,并且辅助用户标签就可从热门item中过滤出用户喜欢的。因此,大众偏好这部分通过简单的召回策略即可实现,而复杂的模型召回可以更关注个性化偏好这部分。 当然,业务场景间差别非常大,笔者的观点在一些场景可能并不适用,仅供参考。
热门item打压
数据角度
通过正样本打压
正样本往往是用户历史正反馈数据,比如点击、转化、收藏、转发,这种样本生成方法自带偏向热门属性,因此直觉的办法就是降低正样本中的热门item样本的比例。但是,正样本又是稀缺的,降低热门item样本量的方法一定程度上损害了数据多样性,需要谨慎使用。
通过负样本打压
增加热门item在负样本的比例,可以使用In-Batch负采样。
也可以根据热度做全局负采样,热度越高被采中概率越大,这样就可以一定程度上对冲掉正样本中的热门item,在一些情况下热门item可能负采样太多导致打压过度(如背景所述笔者认为在多通路召回下问题不大)。比如根据item的点击次数做负采样。
模型角度
如果采用NCE或SSM方法,在打分公式中引入了负样本概率消偏,新的打分公式为:
注意这里只是在训练时打压了热门item,理论上
特征角度
可以观察高分热门item是由哪些特征导致分数高,这样就可以将这些特征替换成非热门item的特征,实现分数打压。不过模型很黑盒,并且特征是异构的、离散的、数量又非常多,定位和替换特征有难度,不一定有可行性。另外强制替换特征会改变打分分布,导致模型评估指标和离线不一致,所以这种方法不太建议使用。
业务角度
从召回本身来看,往往是多通路召回,有些通路关注热门,有些通路关注个性化,这里要避免的就是所有通路都偏向热门。通路间有quota分配,可以人工干预热门通路的占比,甚至根据大盘业务指标实时自动调配。
从整个业务层面来看,召回只是最上游,下游还有粗排精排甚至重排,在排序环节也需要考虑多样性问题,另外也需要有item粒度实时提权或打压的运营干预手段。
参考资料
- [1][Softmax近似方法(一) - Noise Contrastive
Estimation理论详解](https://mathmach.com/b5ec3256/)
- [2][Softmax近似方法(二) - Sampled
Softmax理论详解](https://mathmach.com/b5ec3256/)
- [3][Softmax近似方法(三) - NCE、NEG、Sampled
Softmax对比](https://mathmach.com/a817e3bf/)
- [4][推荐系统传统召回是怎么实现热门item的打压?](https://www.zhihu.com/question/426543628/)