作者 formath 2024-01-02
点击率预估中的特征交互方法
背景
我从事广告算法多年了,经历过点击率模型从XGBoost、大规模离散逻辑回归、FFM到后来DNN的演进。2017年从FFM迁移DNN时,主要考察的是FNN、PNN、DeppFM、Wide&Deep这类模型,特点是特征交互基本沿用了浅层模型的方法,区别是后接了MLP。此后,DNN在CTR领域站稳脚跟后,才开始真正的面向DNN,思考怎样进行特征交互建模,比如吸收了Attention等NLP领域的技术,这一阶段主要思考通用的特征交互方法。近几年,又开始面向某类特征,设计专用的特征交互方法,值得一提的是一系列用户行为序列建模的方法在工业界取得了非常大的收益。本文记录一下对前两个阶段的一些工作的理解,第三阶段以后单独开一篇。
特征交互方法
笛卡尔积
两个离散特征A、B做拼接成特征C,既C = A&B,参数空间为D为embedding
size。DNN在搜广推早期应用时,有些言论说Deep侧不用加组合特征,由mlp隐式学习组合就行,其实效果上是站不住脚的。根据我的经验,在Deep侧加一些组合特征,提供一些人工先验知识,可以帮助模型学习的更好。但组合特征本身也存在问题,这才引出后面很多怎么在模型内部进行特征交叉的结构优化工作。
- 优点:记忆性强,能显著提升模型效果。
- 难点:特征量级大导致模型非常大,需要比较强的工程能力。特征稀疏,存在很多低频组合特征,容易过拟合。一般通过频次准入控制过拟合,但对不同类型的特征组合可能需要不同频次,不太好设定。
- 缺点:泛化性不好,训练中没有出现的特征组合,在预估时查不到。
FM
每个特征有单独的emb,两个特征的emb内积作为交叉。参数空间为
- 优点:有一定泛化性,训练中没有出现的特征组合,在预估时也可以得到内积。
- 缺点:每个特征只有一个emb,与不同特征组合时可能需要不同的emb。比如
A&B = 男性&20岁对美女视频点击率高,A&B = 女性&20岁对帅哥视频点击率高,那20岁这个特征就被互相拉扯,最终指向性不明确了。
FFM
针对FM缺点的优化方案,每个特征,对每个slot,有单独的emb,两个特征的计算内积时,取对应的slot
emb。参数空间为
- 优点:解决了FM的缺点,效果更好。
- 缺点:group聚合设计、group间交叉关系,需要一些经验。
FNN
论文1出发点是DNN学习大规模离散特征的emb太复杂,所以基于预训练FM对每个特征学出一个w和一个v向量,FNN将所有特征的w和v拼接起来过dnn。论文的出发点在当时是存在的,当时并没有能够支持大规模离散特征的开源深度学习框架,只有某些大厂有自研能力,包括百度凤巢第一版DNN时,也是先学习的逻辑回归,然后把逻辑回归的w拼起来过dnn,后面才有的MIO-Framework、Abacus、AI-Box深度学习框架。从方案上看,FM训练时,w是用于reduce sum,v是用于内积,FNN把它们拼起来过mlp,虽然理论上mlp是万能逼近器,能逼近出reduce sum和内积的效果,期待在有个保底的基础上,然后找到一个比reduce sum和内积更好的方程。根据我的经验,w、v和后面的mlp,驴唇不对马嘴,mlp连学习到保底水平都达不到,最终效果还不如FM。
PNN
论文2算是对FM的一个扩展,两个向量内积后,后面接mlp,而不是直接reduce sum。除了内积,也可以使用外积或内外积同时使用。内积PNN相比于FNN,不同的是向量端到端训练,可以适应mlp,而不像FNN那样驴唇不对马嘴。内积和外积算是比较基础的交互方法了,在其他模型比如NLP里应用也比较广泛,可以作为最基础的特征交互方法。
NFM
论文12和PNN有点像,不同的是两个向量做哈达玛积,后面接mlp。有个AFM类似的工作,两个向量哈达玛积的基础上,再乘个attention,感觉有点多余。
DeepFM
论文3和Wide&Deep差不多,叫FM&Deep更合适,论文把Wide侧换成FM模型,并且FM侧的emb和Deep侧的emb是共享的。这个结构在工业界用的挺多,不过和论文有一些不同点,比如FM侧和Deep侧的emb不共享、FM侧用FFM。
Deep Crossing
7加了个Residual,没啥好说的。之前在ffm迁dnn时试过,没用。
DCN
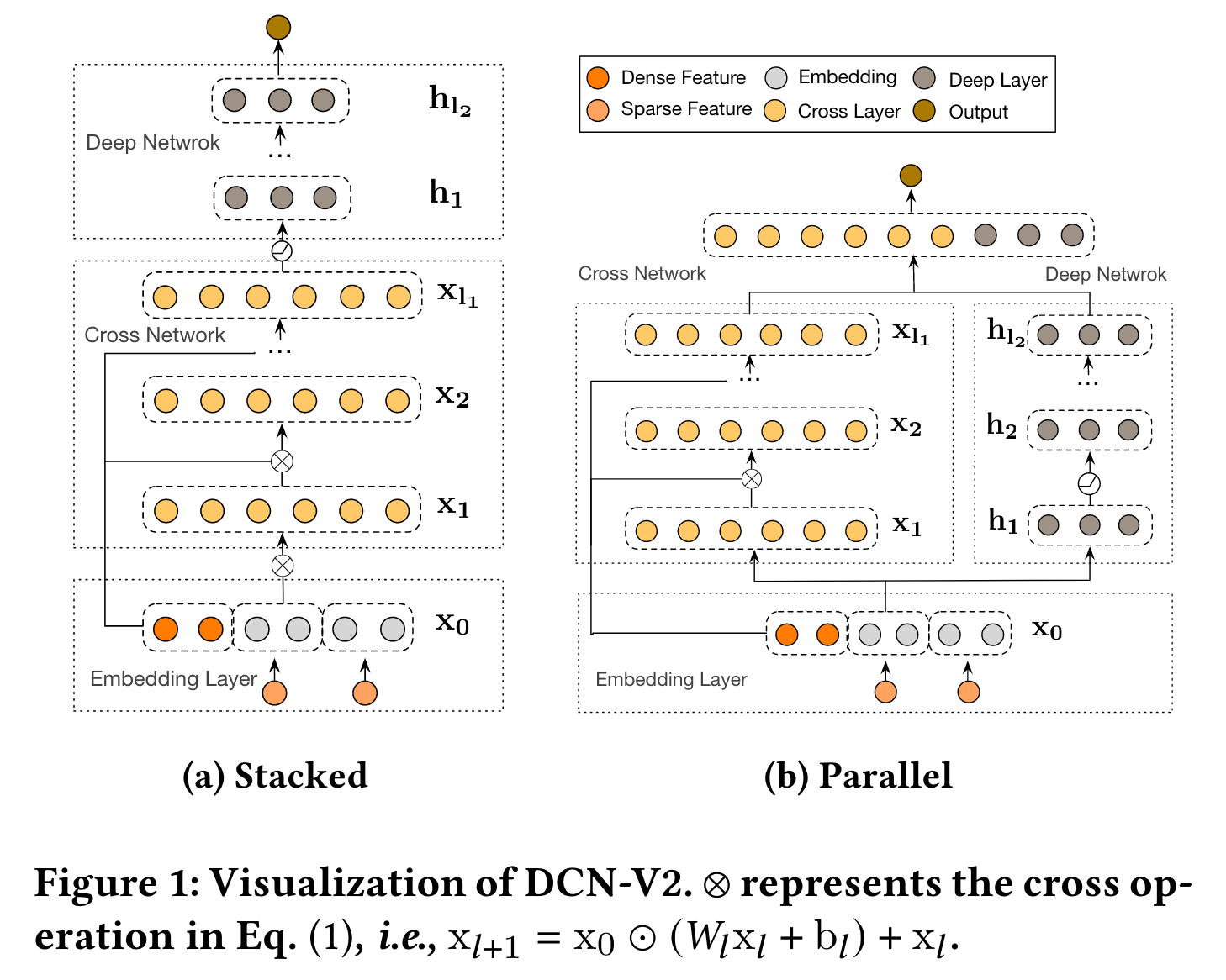
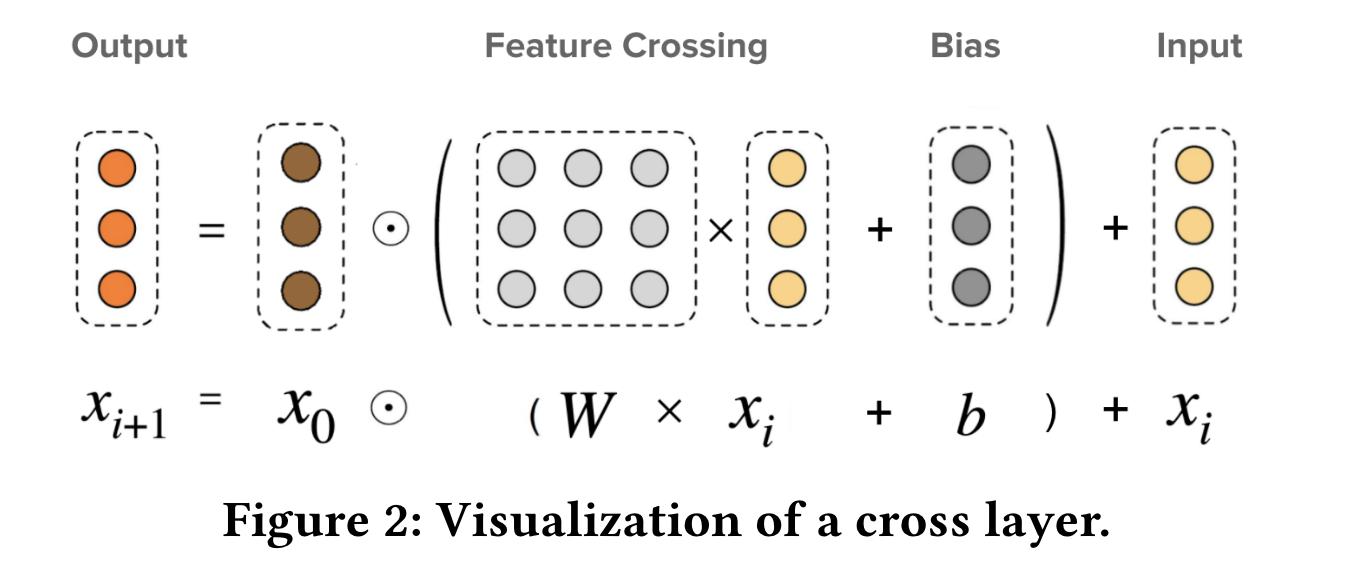
4把所有特征的emb起来后,每层通过简单乘法进行特征交叉,层数越多交叉越高阶,后面又出了个v2版5。DCN是bit-wise交互,并且只用最高阶的输出作为MLP输入。我之前在ffm迁dnn时试过v1版,效果不如wide&deep。
V2的结构如下:
xDeepFM
6每个slot emb间做哈达玛积,再过一个全连接网络,然后累加起来,得到下一层某个slot的emb。每次计算下一层一个slot emb,相当于遍历了所有高阶组合,多个slot有一点multi-head的作用,每个slot关注不同层面的组合。最后把所有阶的emb pooling起来过mlp。与DCN不同,xDeepFM关注slot-wise的交互,并且每阶的交互都保留下来过MLP。
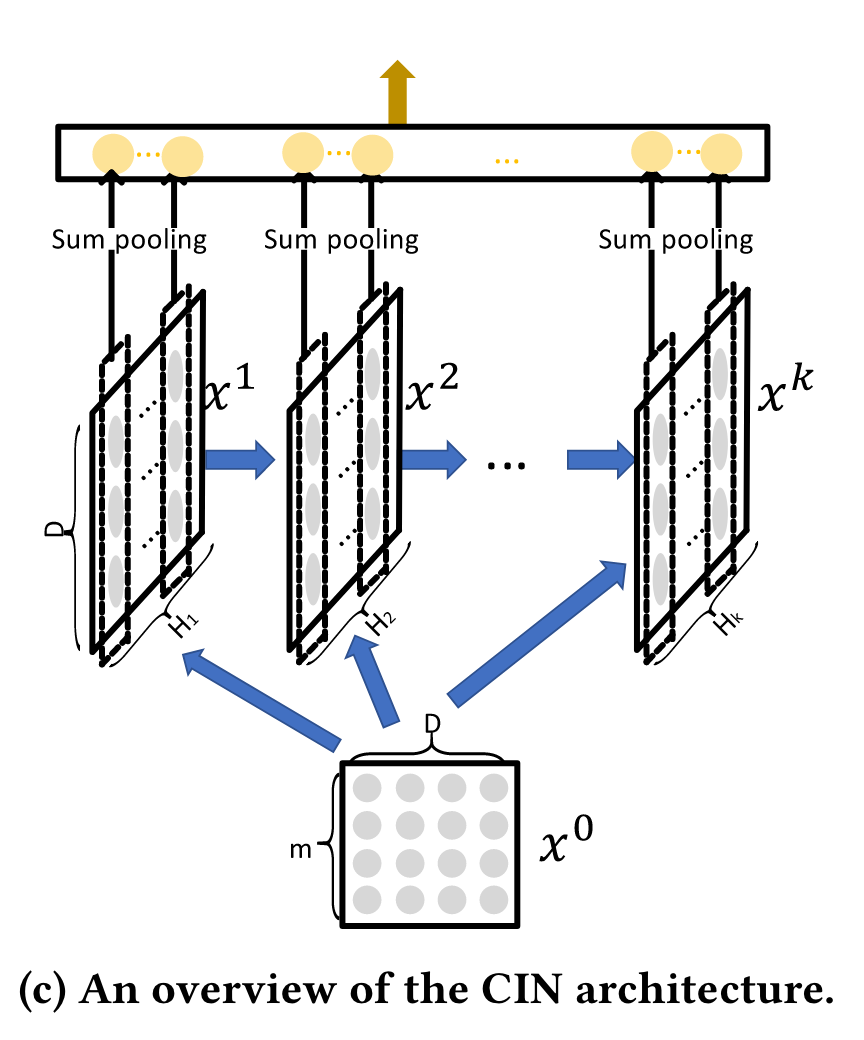
难点:nn参数和计算量有点大,不太清楚有哪些工业界落地。
FiBiNET
14内积和哈达玛积太简单,FiNiNET里它俩结合了一下,叫做Bi-Linear Interaction,如下图。
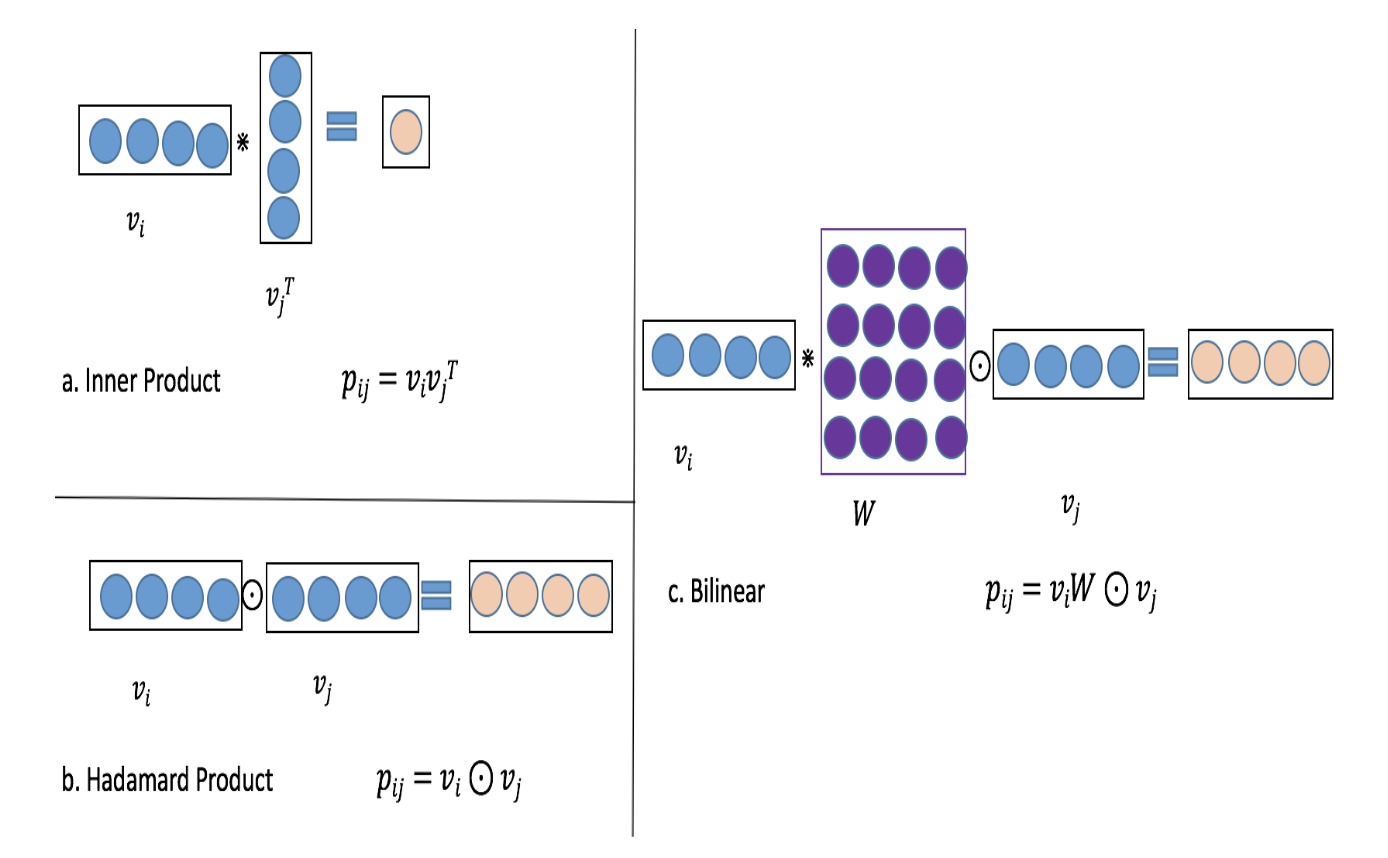
论文另一个主要贡献是引入了SENet,学习特征的权重,权重作用到原始emb后得到新emb。然后,在原始emb和新emb上分别使用Bi-Linear Interaction进行二阶交互,然后全拼起来过mlp。
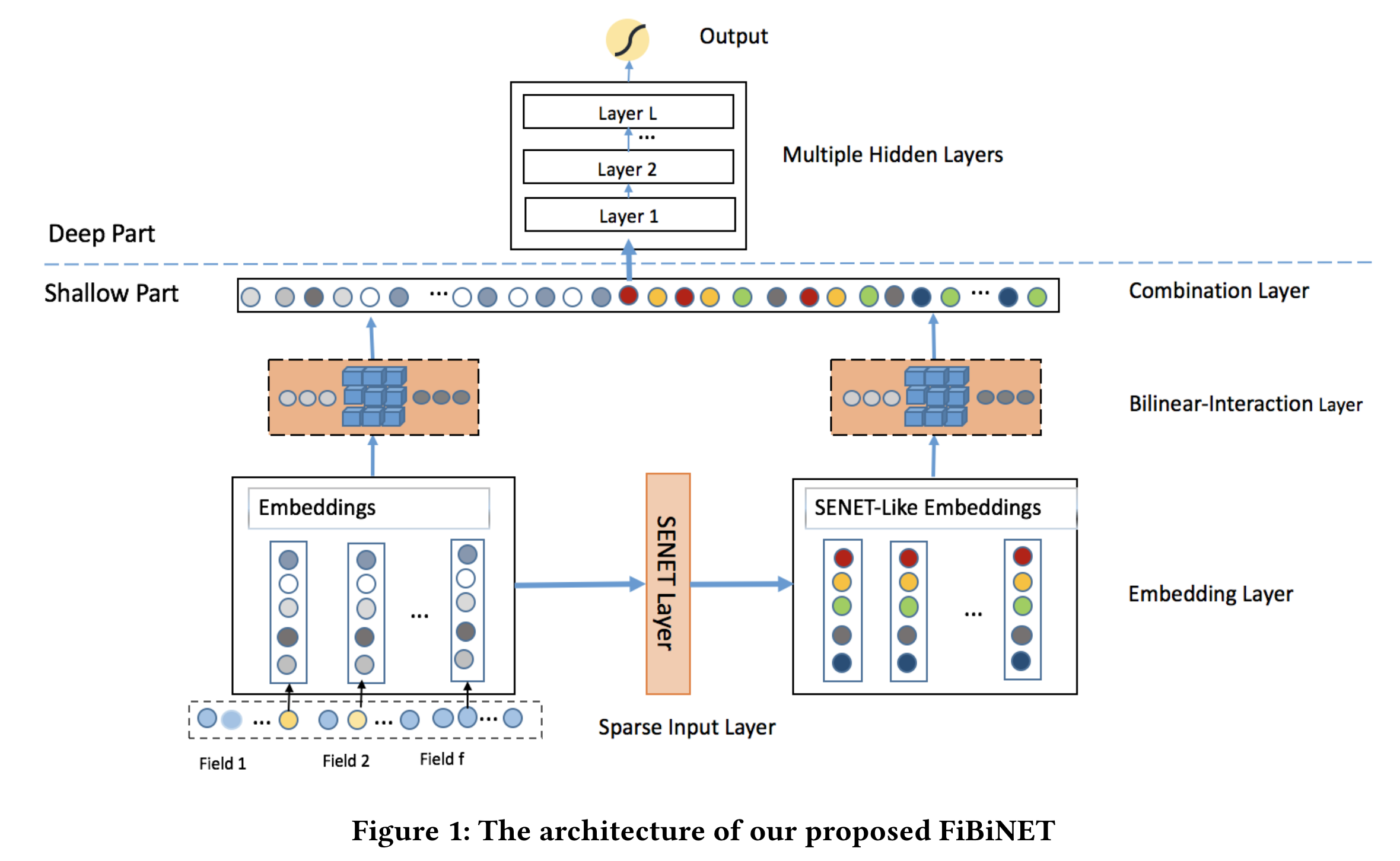
SENet后来在粗排用的挺多的,用于淘汰一些没用的特征,提升模型速度。Bi-Linear Interaction的话不太了解哪些厂有落地。 FiNiNET的特征交互后太宽,FiNiNET++15对它进行了优化。
AutoInt
8每个slot得到emb后,对所有slot做multi-head attention,得到融合了交互信息的slot emb。和xDeepFM类似,都是slot-wise交互。xDeepFM像RNN一样,下一阶的交互要依赖更浅一阶的交互,如果AutoInt做多层multi-head attention,也能获得高阶交互。
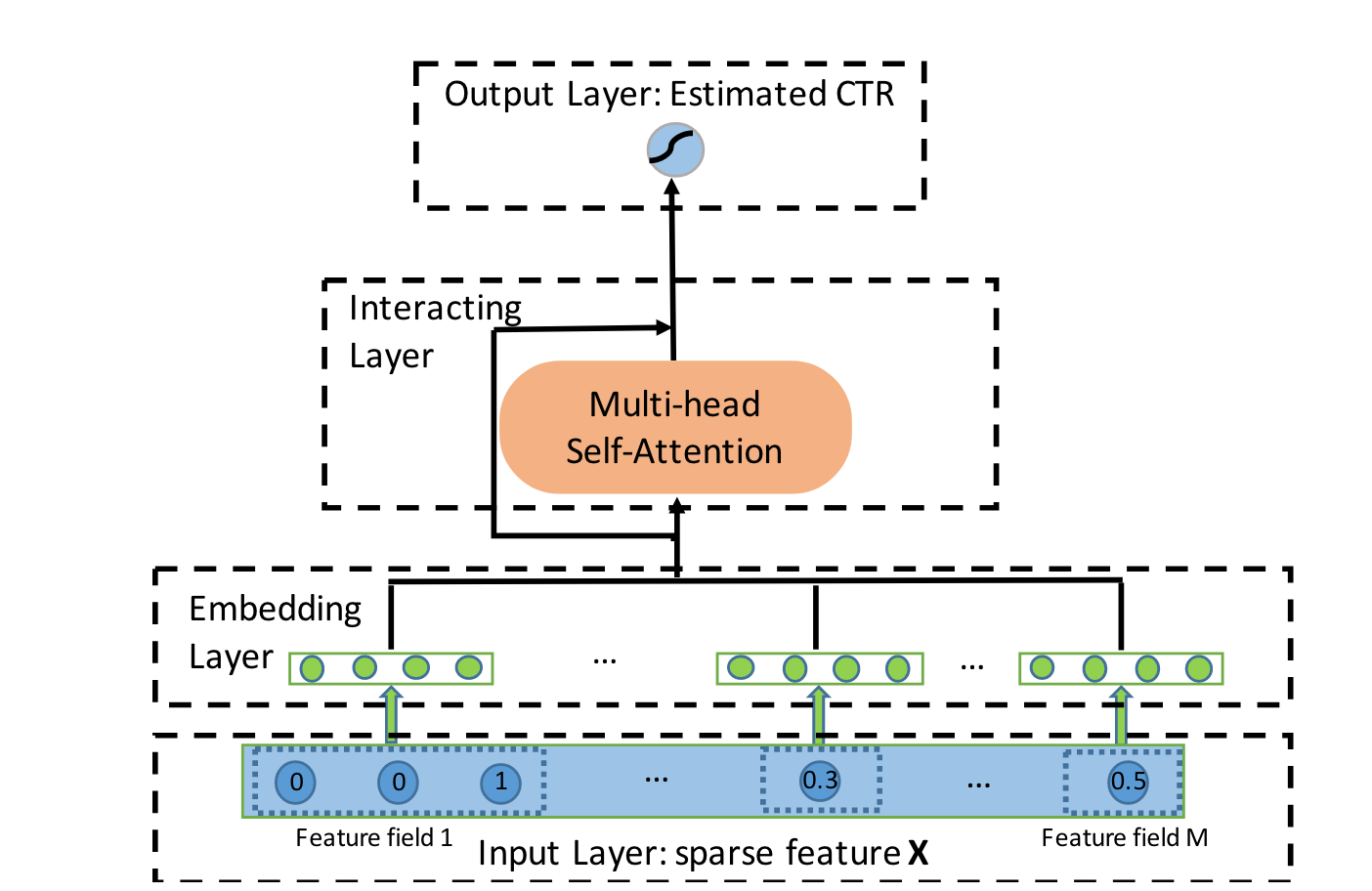
- 难点:计算量有点大。学术界作品,不清楚工业界有没有落地。
Co-Action Unit
9阿里妈妈提出的,在两个离散特征A、B做交叉时,把A的emb拆分成mlp每层的参数,B的emb作为mlp输入,mlp的输出向量作为交叉结果。
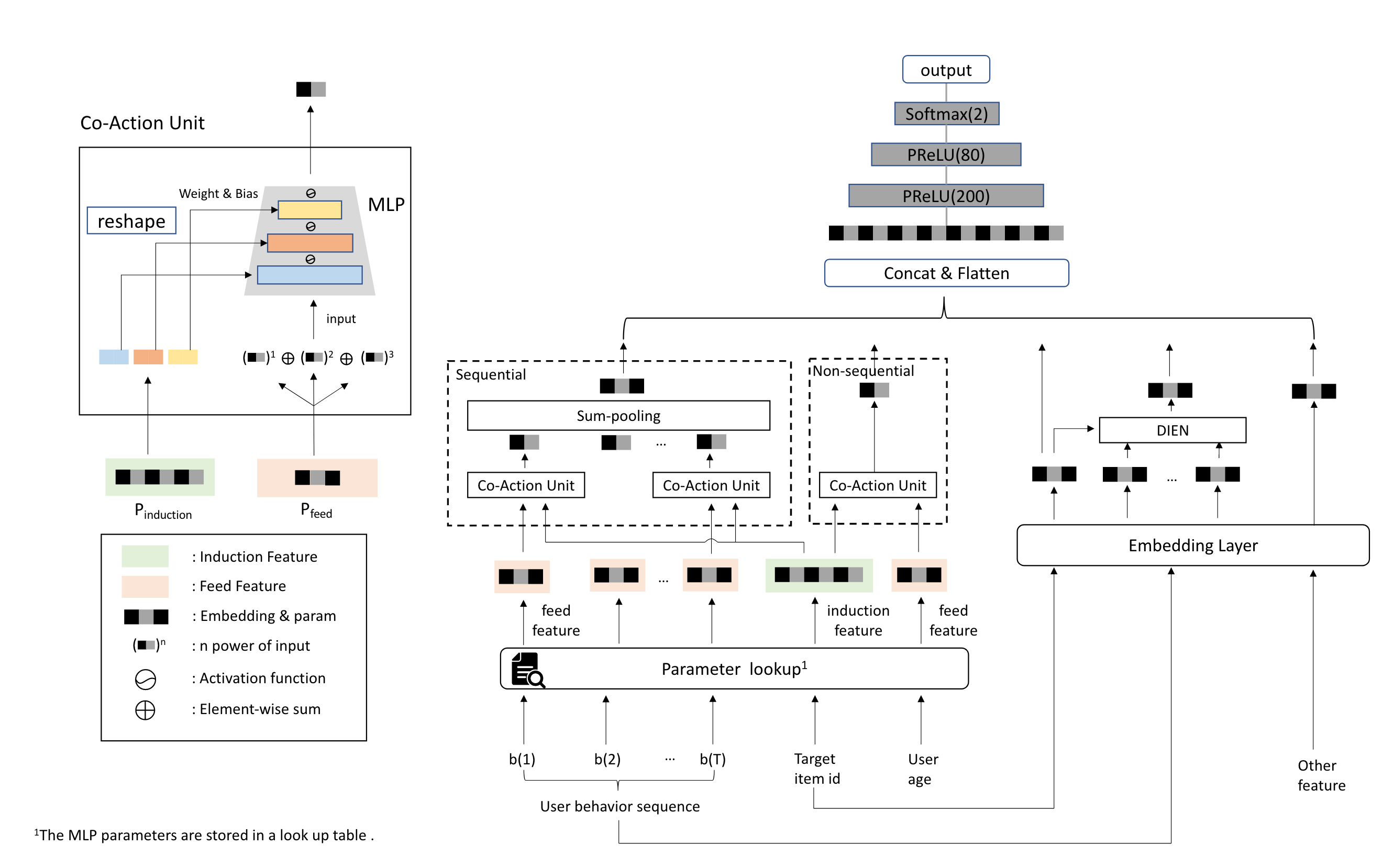
参数空间为
参考
- [1][Deep Learning over Multi-field Categorical Data: A Case Study on
User Response Prediction](http://arxiv.org/abs/1601.02376)
- [2][Product-based Neural Networks for User Response
Prediction](http://arxiv.org/abs/1611.00144)
- [3][DeepFM: A Factorization-Machine based Neural Network for CTR
Prediction](http://arxiv.org/abs/1703.04247)
- [4][Deep & Cross Network for Ad Click
Predictions](https://arxiv.org/abs/1708.05123)
- [5][DCN V2: Improved Deep & Cross Network and Practical Lessons
for Web-scale Learning to Rank Systems](http://arxiv.org/abs/2008.13535)
- [6][xDeepFM: Combining Explicit and Implicit Feature Interactions
for Recommender Systems](http://arxiv.org/abs/1803.05170)
- [7][Deep Crossing: Web-Scale Modeling without Manually Crafted
Combinatorial
Features](http://www.kdd.org/kdd2016/papers/files/adf0975-shanA.pdf)
- [8][AutoInt: Automatic Feature Interaction Learning via
Self-Attentive Neural Networks](http://arxiv.org/abs/1810.11921)
- [9][CAN: Feature Co-Action for Click-Through Rate
Prediction](https://arxiv.org/abs/2011.05625)
- [10][想为特征交互走一条新的路](https://zhuanlan.zhihu.com/p/287898562)
- [11][特征交互新思路|阿里 Co-action
Network论文解读](http://xtf615.com/2021/01/10/can/)
- [12][Neural Factorization Machines for Sparse Predictive
Analytics](http://arxiv.org/abs/1708.05027)
- [13][如何在工业界优化点击率预估:(五)特征交叉建模](https://zhuanlan.zhihu.com/p/489284765)
- [14][FiBiNET: Combining Feature Importance and Bilinear feature
Interaction for Click-Through Rate
Prediction](http://arxiv.org/abs/1905.09433)
- [15][FiBiNet++: Reducing Model Size by Low Rank Feature Interaction Layer for CTR Prediction](http://arxiv.org/abs/2209.05016)