作者 formath 2023-05-31
Transformer量化分析(一) - 模型参数分析
背景
ChatGPT出现后,惊人的效果完全颠覆了业界人员包括笔者的认知,抛开其模型细节层面的因素,已公开的训练方法,需要巨量的数据和计算资源,门槛非常高。本文基于公开资料,希望以量化方式分多篇介绍ChatGPT的分析结论,具体内容包含以下三篇,本文为模型参数分析篇。
模型结构
基于Transformer结构的encoder-decoder模型如图: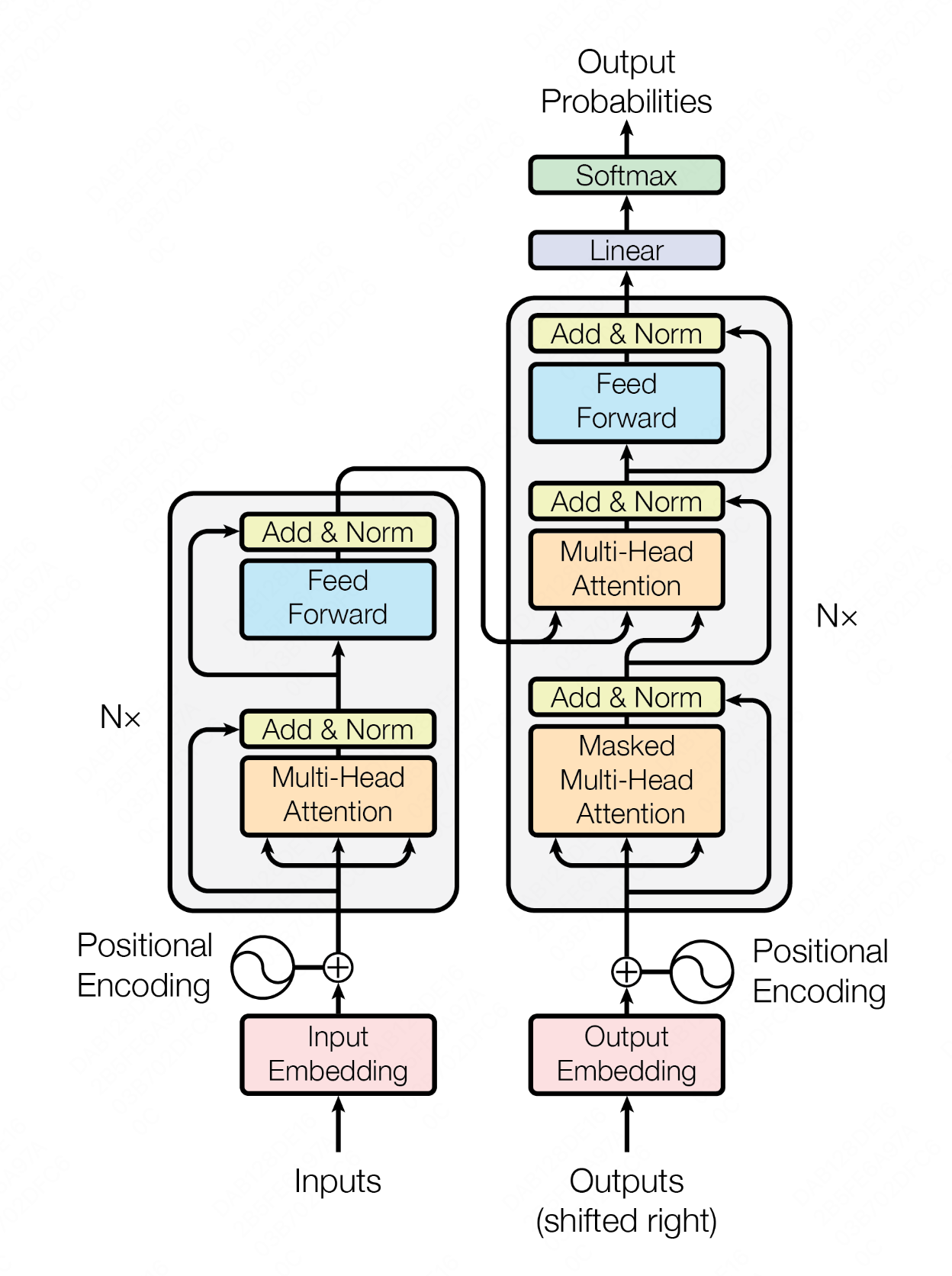
encoder编码器将输入词序列
参数量分析
输入词序列
Embedding层
变量定义:
Transformer Blocks层
transformer block计算图如下,每个transformer block的参数分布在两部分中,既multi-head attention和mlp。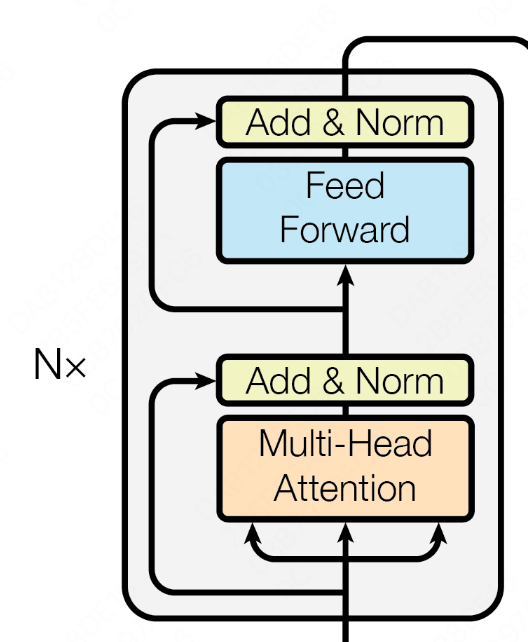
Multi-head Attention
multi-head attention结构如图: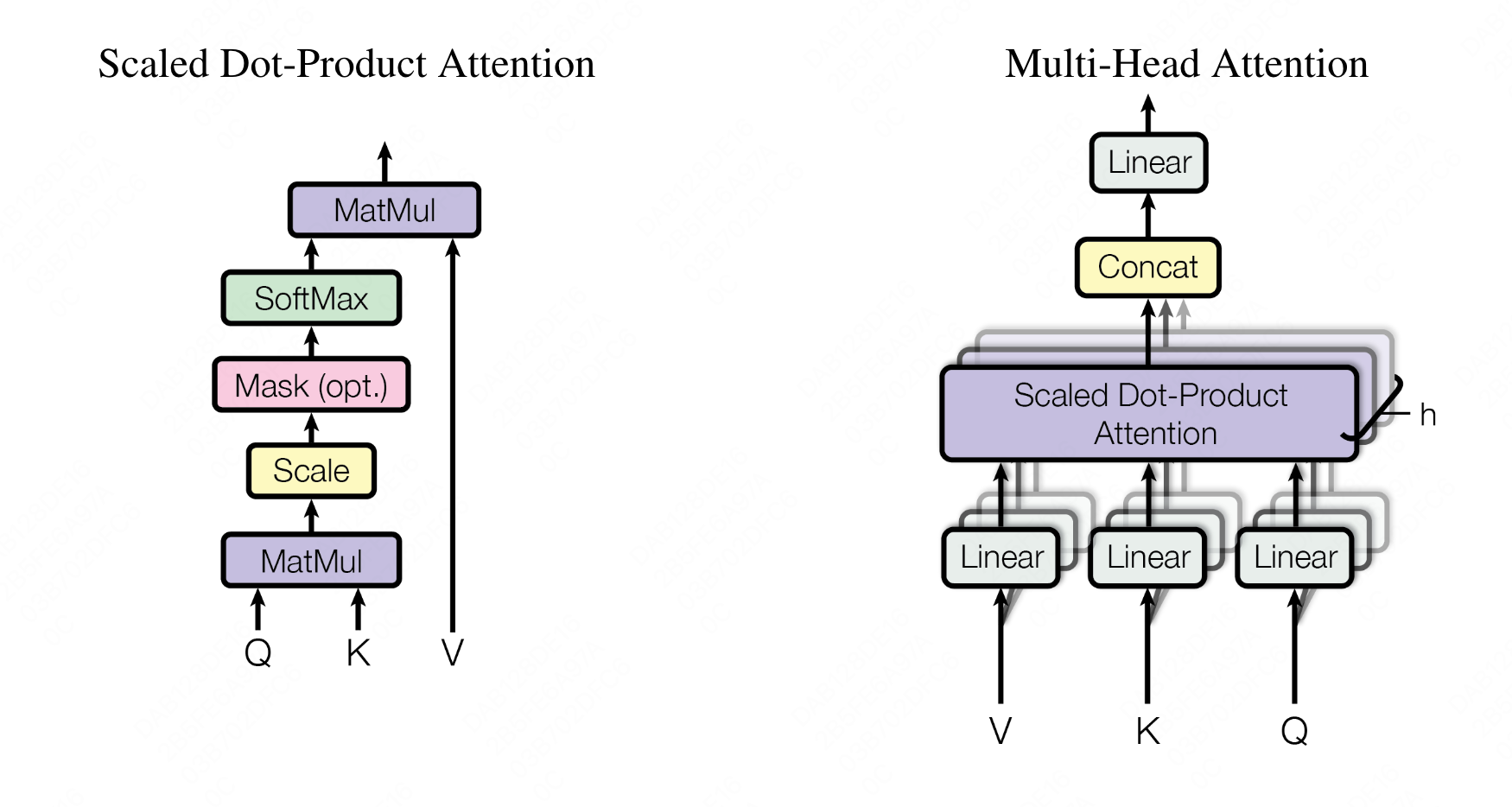
变量定义:
MLP
multi-head attention后面,接两层的全连接网络,计算逻辑为:
所以,mlp的参数量为:
Transformer Block参数量
根据multi-head attention和mlp,得到每个transformer block的参数量为:
模型总参数量
最终,Transformer的总参数量为:
在GPT3中,
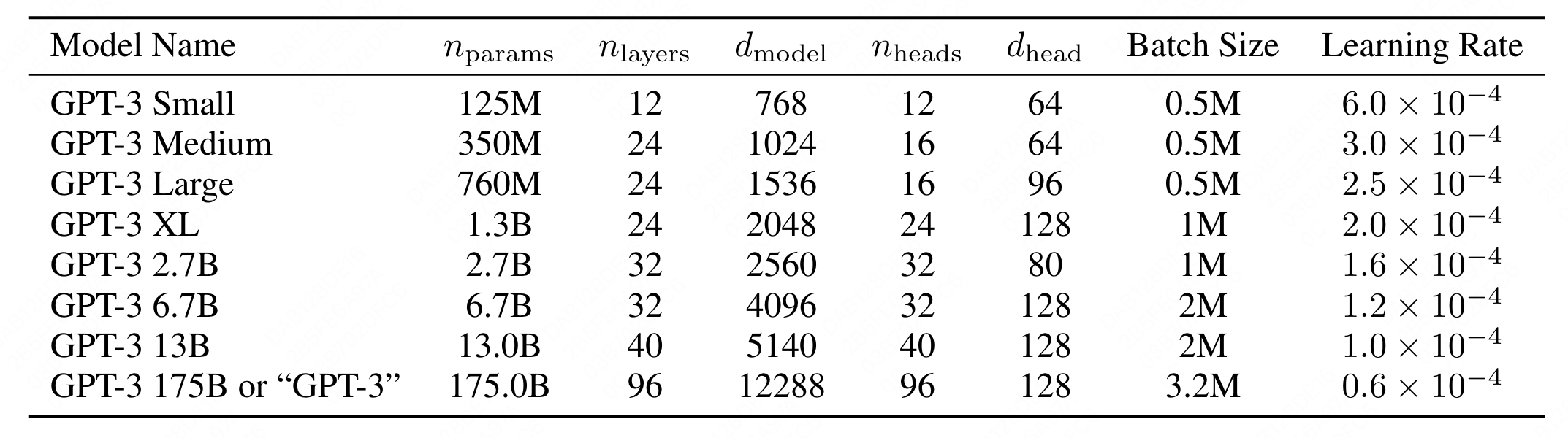
各个参数对模型大小的影响力度不同,这里需要特别注意
各配置对总参数量的影响
对参数配置进行求导,得到:
| 参数配置 | 梯度值 |
|---|---|
| 14175872 | |
| 2359392 | |
| 452984832 | |
| 1812000768 | |
| 603979776 |
可以看到,