作者 formath 2023-06-01
Transformer量化分析(二) - 存储占用分析
背景
ChatGPT出现后,惊人的效果完全颠覆了业界人员包括笔者的认知,抛开其模型细节层面的因素,已公开的训练方法,需要巨量的数据和计算资源,门槛非常高。本文基于公开资料,希望以量化方式分多篇介绍ChatGPT的分析结论,具体内容包含以下三篇,本文为存储占用分析篇。
ChatGPT模型结构为Transformer,Transformer模型运行时存储可以分成两部分,其一是模型参数,这部分规模是固定的,其二是中间激活,这部分和batch size、sequence length有线性关系,下面对两者分别分析。
模型参数
变量定义:
训练阶段
在训练阶段,采用Adam优化器,先看下Adam的公式SGD优化算法的各种变体。
Adam超参数:
- 学习率
- 惯性项
- 惯性项
- 衰减率
Adam更新公式:
Adam中有
推理阶段
推理阶段只有前向过程,用float16存储的话,存储占用为:
中间激活
变量定义:
TensorFlow、PyTorch、MXNet等深度学习框架以逻辑计算图描述模型,以运行时计算图启动计算,计算图以Tensor(数据)和Operatopn(算子)组织,Operation依赖输入Tensor,通过内部计算得到输出Tensor。更具体一点,前向计算过程中,Operation接收上一Operation产出的激活Tensor和本Operation模型参数Tensor,计算得到激活Tensor给下游Operation,既:
下面按Operation进行分析。训练阶段经常使用混合精度训练,推理阶段也会采用量化,因此下面统一以半精度float16(2 bytes)进行浮点存储和计算。
Embedding
embedding层是lookup操作,输入是词序列,输出形状是
Transformer Blocks
transformer block的计算图如下,每个transformer block主要包含四部分,既multi-head attention和mlp,以及两个add&norm。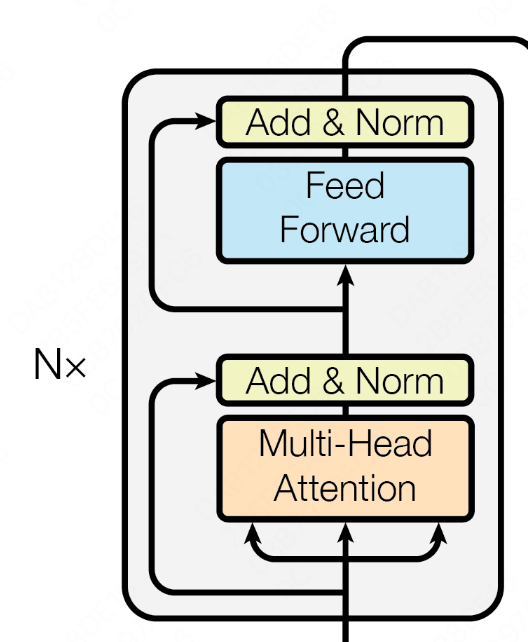
Multi-head Attention
multi-head attention结构如图: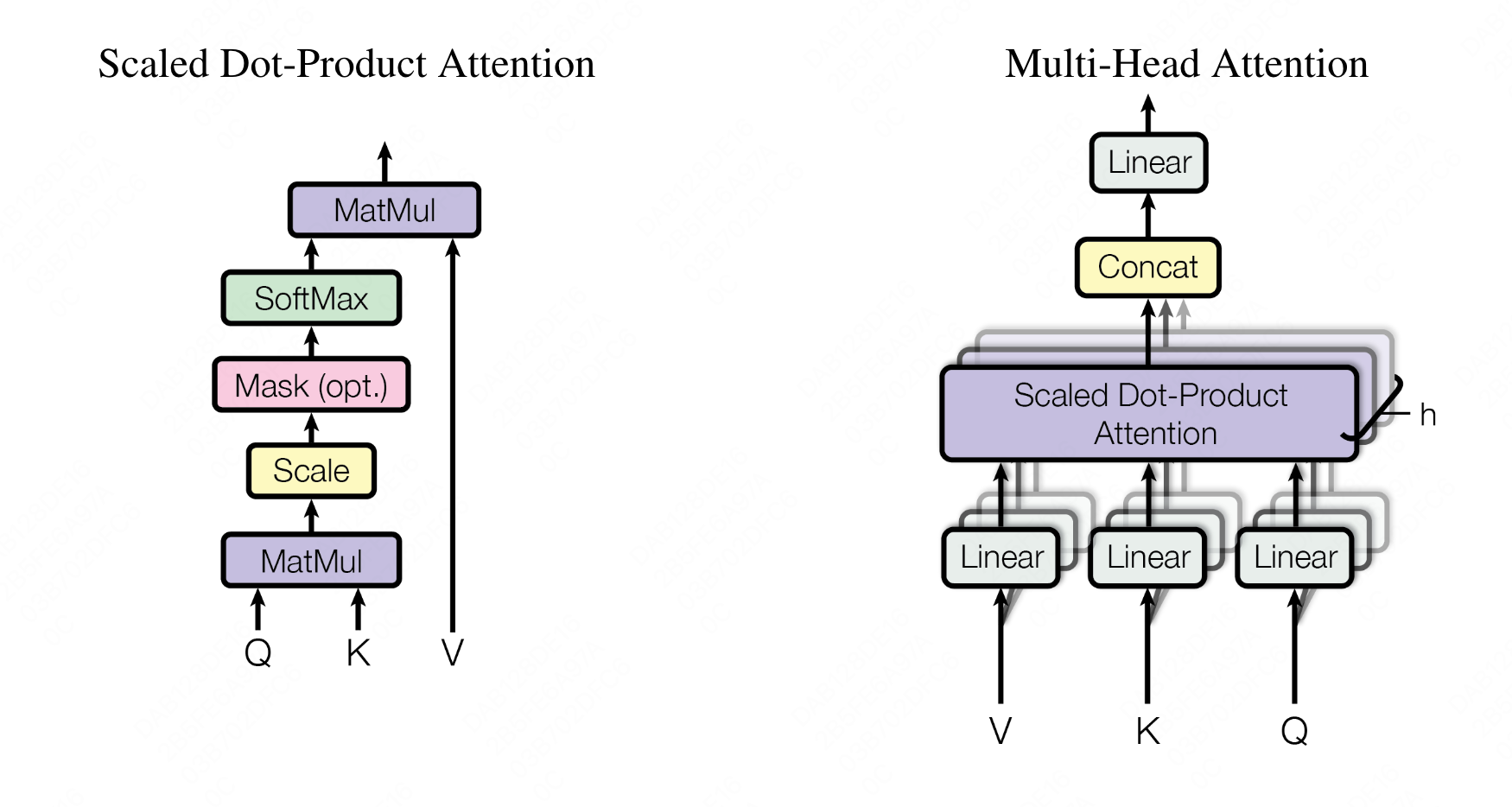
变量定义:
- 矩阵乘法算子
的输入激活Tensor是E,E在第一个block是词本身embedding和position embedding之和,在其他block是上游block的输出,E的形状为 ,乘法输出Tensor形状为 ,因此存储占用为 , 和 同 ; - Softmax算子的输入Tensor为
和 ,输出形状为 ,存储占用为 ; 的输入Tensor为 和 ,输出为 ,存储为 ; - 每个head的存储为
,共 个head,存储占用为: ; - concat的输入为
个 ,输出为 ,存储为 ; 输入为激活 和参数 ,输出为 ,因此存储为 。
实际实现时,往往不会使用concat,而是将多头的Q、K、V合并成大矩阵,因此将concat存储忽略。综上,multi-head
attention的输入存储总占用为:
MLP
multi-head attention后面,接两层的全连接网络,计算逻辑为:
- 矩阵乘法算子
的输入激活Tensor x是multi-head attention输出,形状为 ,输出Tensor形状为 ,因此存储占用为 ; 加法部分输入是激活 和参数 ,输出是 ,存储占用为 ; 输入和输出都是 ,输入存储为 ; 的输入是激活 和参数 ,输出是 ,输入存储为 ; 加法部分输入是激活 和参数 ,输出是 ,输入存储占用为 ;
综上,mlp部分的存储占用为:
Add&Norm
add部分的输入激活可以与multi-head
attention和mlp里的输入共享存储,因此不用计算。norm的输入和输出都是
中间激活存储占用
综上,每个transformer block的存储占用为:
训练阶段
在训练阶段,中间激活需要保留用于反向传播的梯度计算,并且每个激活tensor都对应一个梯度tensor,因此存储占用翻倍,既
| 中间激活存储(GB) | |
|---|---|
| 128 | 42624 |
| 512 | 170496 |
| 1024 | 340992 |
| 4096 | 1363968 |
这里将较小的embedding存储忽略,可以看到,相比模型参数部分占用的2595GB,中间激活存储占比更大,需要借助混合并行(数据并行、流水并行、模型并行)、recompute、ZeRO等技术来解决。在batch为128时,存储消耗2595+42624G,需要近600张A100 80G卡。
推理阶段
在推理阶段,中间激活使用完成后可以立即释放。多个block串行计算,block间可以共享内存。block内部有些tensor也串行依赖,tensor使用完成后即可释放。因此,推理阶段最大存储占用比单block存储大小