作者 formath 2025-02-24
细说DeepSeek MLA矩阵消融
背景
DeepSeek-V2论文1中提出了新的Attention模块Multi-head Latent Attention(MLA),通过Lora和矩阵消融的方式将KV Cache大幅缩小,但矩阵消融只是一笔带过,本文细说一下过程。
符号定义
MLA的计算逻辑
矩阵消融过程
消融
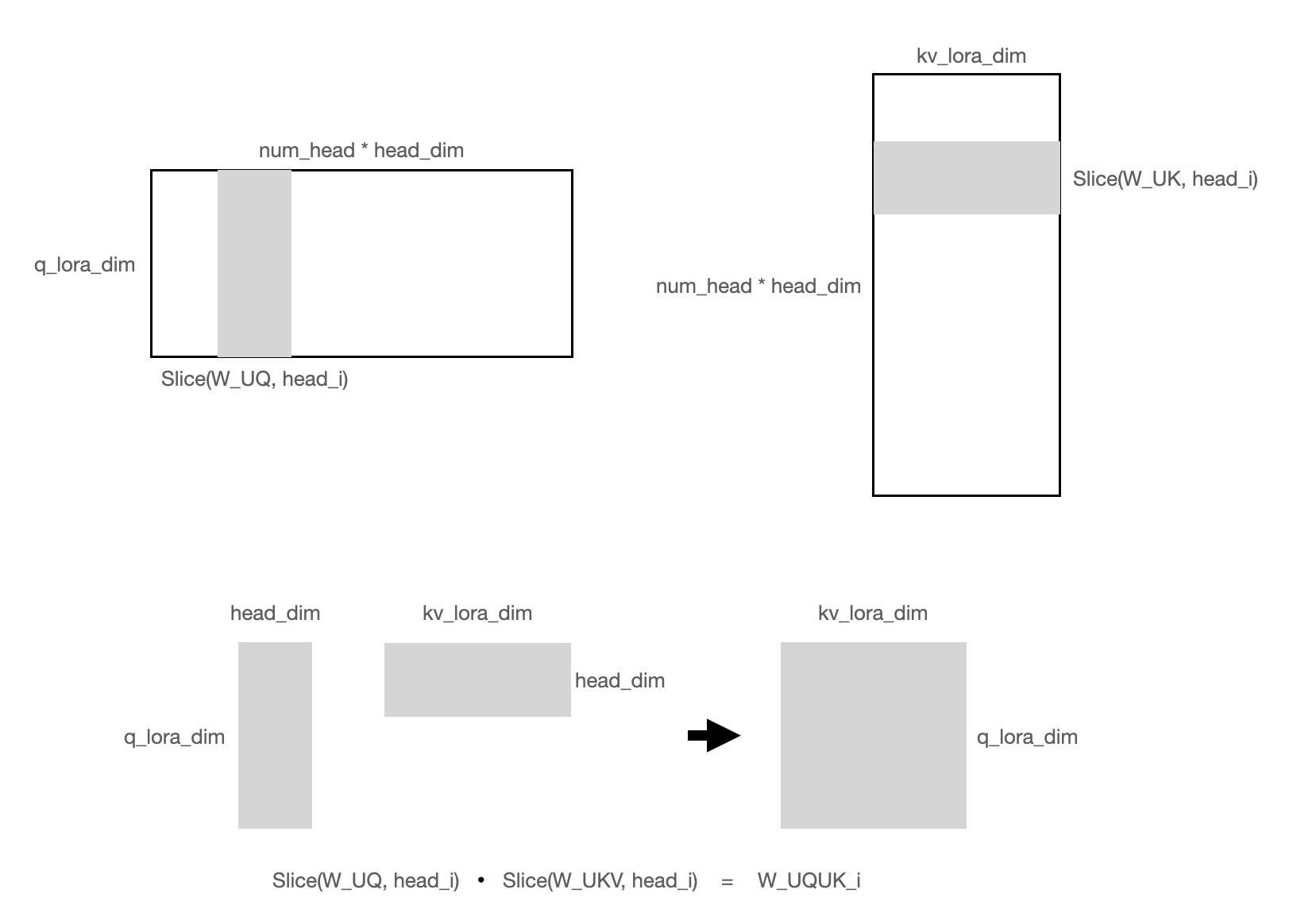
代码表述: # 消融W_UK
W_UQ = tf.reshape(W_UQ, [q_lora_dim, num_head, head_dim])
W_UQ = tf.transpose(W_UQ, perm=[1, 0, 2]) # [num_head, q_lora_dim, head_dim]
W_UK = tf.reshape(W_UK, [kv_lora_dim, num_head, head_dim])
W_UK = tf.transpose(W_UK, perm=[1, 2, 0]) # [num_head, head_dim, kv_lora_dim]
W_UQUK = tf.matmul(W_UQ, W_UK) # [num_head, q_lora_dim, kv_lora_dim]
# 计算qk内积
c_Q = tf.reshape(c_Q, [batch_size, q_seq_len, q_lora_dim])
c_KV = tf.reshape(c_KV, [batch_size, kv_seq_len, kv_lora_dim])
c_KV = tf.transpose(c_KV, perm=[0, 2, 1]) # [batch_size, kv_lora_dim, kv_seq_len]
c_Q_product_W_UQUK = tf.einsum('bij,hjk->bhik', c_Q, W_UQUK) # [batch_size, num_head, q_seq_len, kv_lora_dim]
q_product_k = tf.einsum('bhik,bkj->bhij', c_Q_product_W_UQUK, c_KV) # [batch_size, num_head, q_seq_len, kv_seq_len]
消融
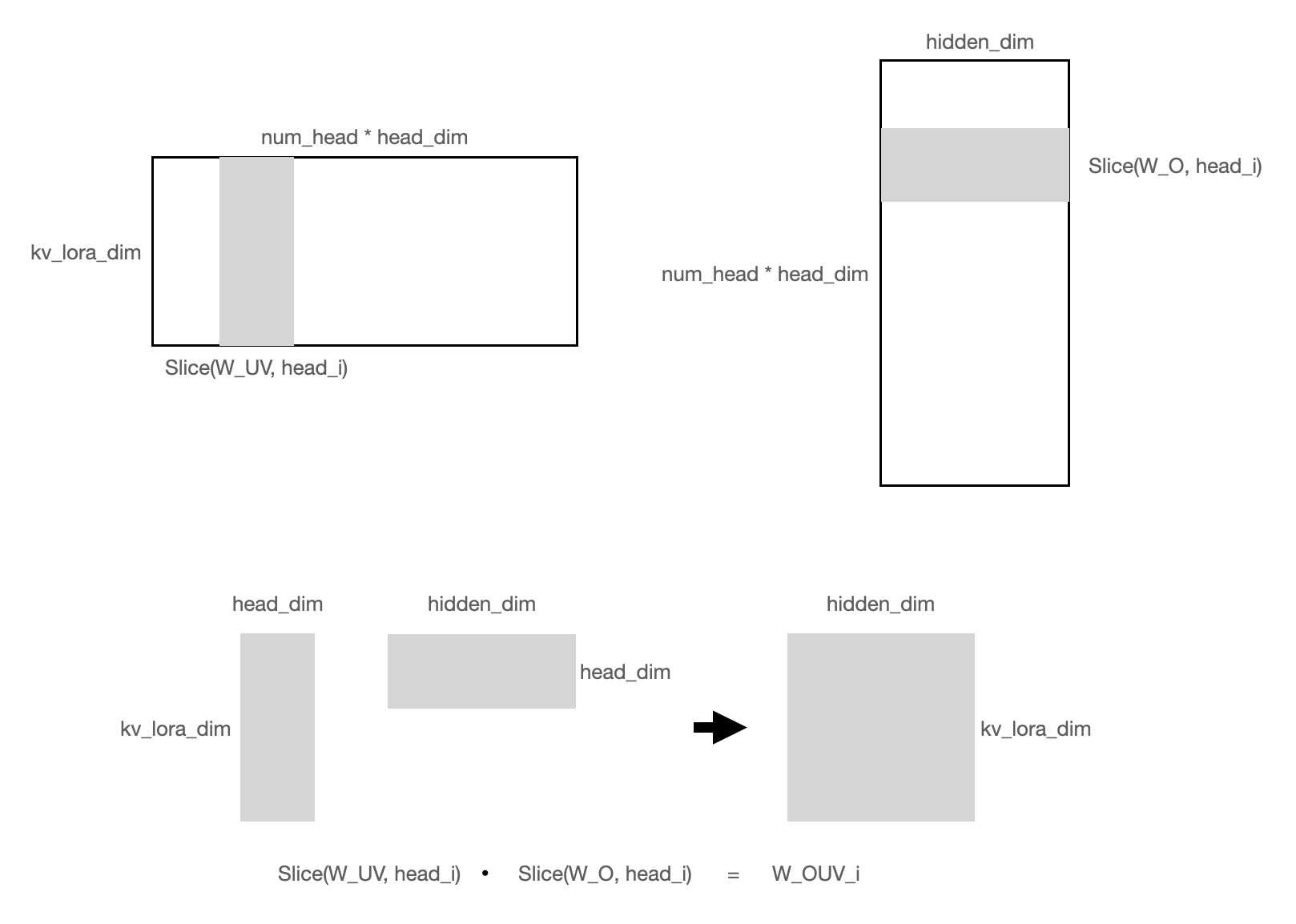
代码表述: # 消融W_UV
W_O = tf.reshape(W_O, [num_head, head_dim, hidden_dim])
W_UV = tf.reshape(W_UV, [kv_lora_dim, num_head, head_dim])
W_UV = tf.transpose(W_UV, perm=[1, 0, 2]) # [num_head, kv_lora_dim, head_dim]
W_OUV = tf.matmul(W_UV, W_O) # [num_head, kv_lora_dim, hidden_dim]
# 计算u
q_R = RoPE(tf.matmul(c_Q, W_QR)) # [batch_size, q_seq_len, num_head, rope_dim]
k_R = RoPE(tf.matmul(h, W_KR)) # [batch_size, kv_seq_len, rope_dim]
q_product_k_rope = tf.einsum('bijk,bhk->bijh', q_R, k_R) # [batch_size, q_seq_len, num_head, kv_seq_len]
q_product_k_rope = tf.transpose(q_product_k_rope, perm=[0, 2, 1, 3]) # [batch_size, num_head, q_seq_len, kv_seq_len]
attention_weight = tf.softmax((q_product_k + rope_score) / tf.sqrt(head_dim + rope_dim)) # [batch_size, num_head, q_seq_len, kv_seq_len]
c_KV = tf.transpose(c_KV, perm=[0, 2, 1]) # [batch_size, kv_lora_dim, kv_seq_len]
attention_weight_product_c_KV = tf.einsum('bijk,bhk->bijh', attention_weight, c_KV) # [batch_size, num_head, q_seq_len, kv_lora_dim]
u = tf.einsum('bijh,ihd->bjd', attention_weight_product_c_KV, W_OUV) # [batch_size, q_seq_len, hidden_dim]
矩阵消融优化之后的MLA计算逻辑
代码表述: # 这里没考虑kv cache
'''
inputs:
h_q: [batch_size, q_seq_len, hidden_dim]
h_kv: [batch_size, kv_seq_len, hidden_dim]
outputs:
u: [batch_size, q_seq_len, hidden_dim]
'''
# query
c_Q = tf.matmul(h_q, W_DQ)
c_Q = tf.reshape(c_Q, [batch_size, q_seq_len, q_lora_dim])
q_C = tf.einsum('bij,hjk->bihk', c_Q, W_UQUK) # [batch_size, q_seq_len, num_head, kv_lora_dim]
q_R = RoPE(tf.matmul(c_Q, W_QR)) # [batch_size, q_seq_len, num_head, rope_dim]
q = tf.concat([q_C, q_R], axis=-1) # [batch_size, q_seq_len, num_head, kv_lora_dim+rope_dim]
# key value
c_KV = tf.matmul(h_kv, W_DKV)
c_KV = tf.reshape(c_KV, [batch_size, kv_seq_len, kv_lora_dim]) # [batch_size, kv_seq_len, kv_lora_dim]
k_R = RoPE(tf.matmul(h_kv, W_KR)) # [batch_size, kv_seq_len, rope_dim]
k = tf.concat([c_KV, k_R], axis=-1) # [batch_size, kv_seq_len, kv_lora_dim+rope_dim]
# attention(can use FlashAttention)
q_product_k = tf.einsum('bijk,bhk->bjih', q_C, c_KV) # [batch_size, num_head, q_seq_len, kv_seq_len]
attention_weight = tf.softmax(q_product_k / tf.sqrt(head_dim + rope_dim)) # [batch_size, num_head, q_seq_len, kv_seq_len]
c_KV = tf.transpose(c_KV, perm=[0, 2, 1]) # [batch_size, kv_lora_dim, kv_seq_len]
attention_weight_product_c_KV = tf.einsum('bijk,bhk->bijh', attention_weight, c_KV) # [batch_size, num_head, q_seq_len, kv_lora_dim]
# output for next layer
u = tf.einsum('bijh,ihd->bjd', attention_weight_product_c_KV, W_OUV) # [batch_size, q_seq_len, hidden_dim]
MLA的变化分析
降低KV Cache
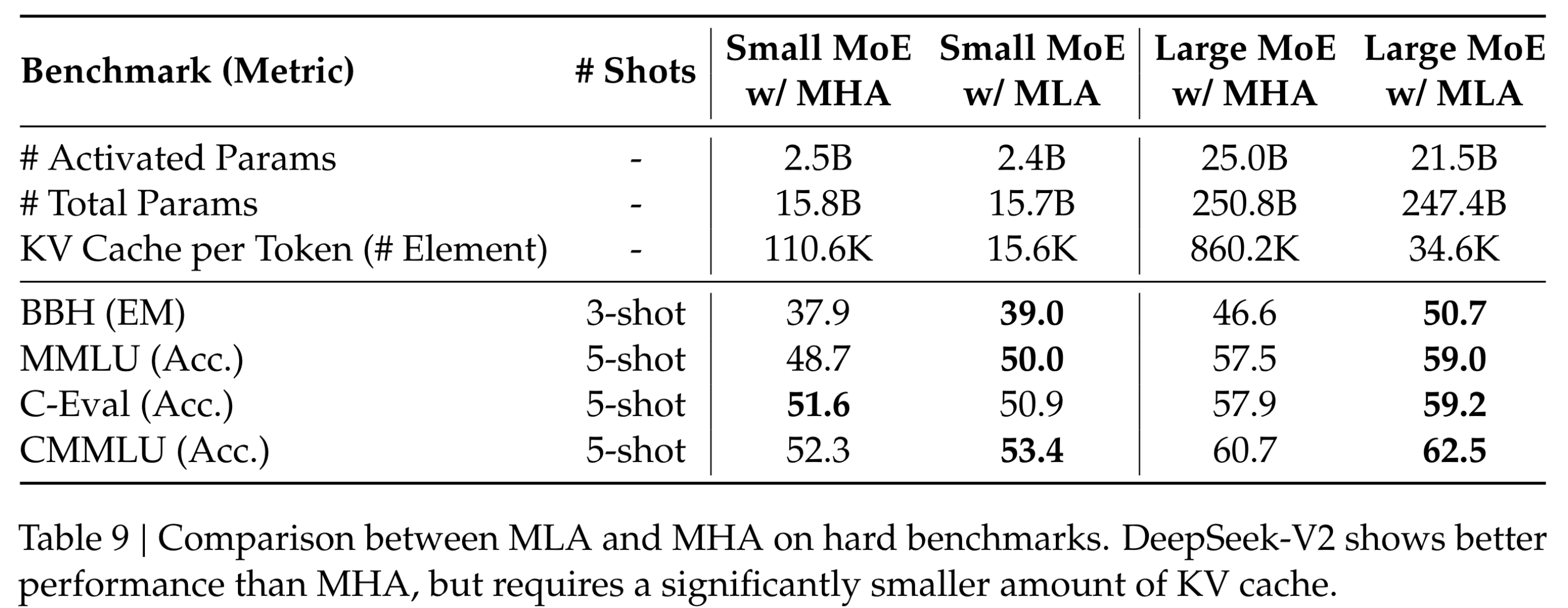
经典的MHA kv cache大小为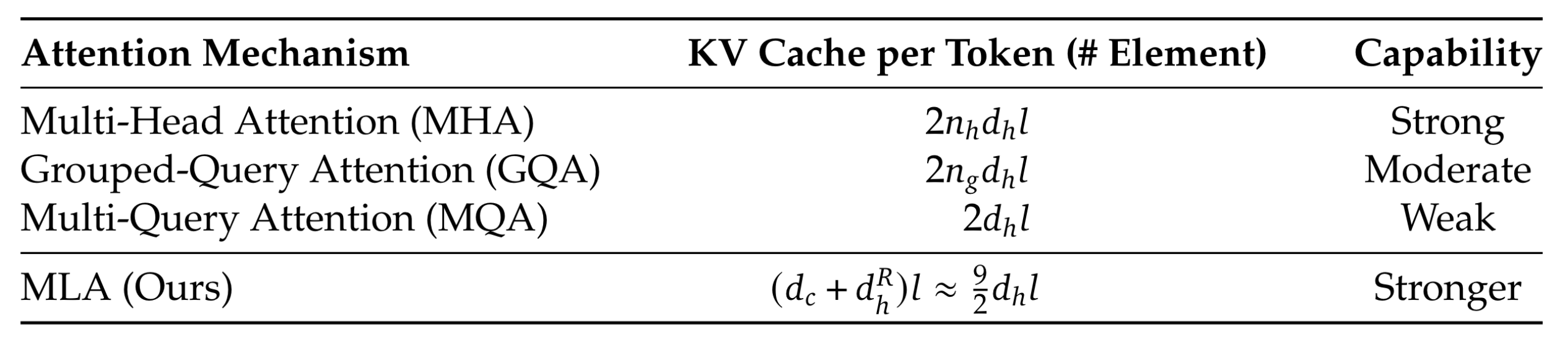
兼容RoPE
MHA中,RoPE得到一个
MLA中,RoPE向量不能直接加到
参考
- [1][DeepSeek-V2: A Strong, Economical, and Efficient
Mixture-of-Experts Language Model](http://arxiv.org/abs/2405.04434)
- [2][DeepSeek-V2 高性能推理 (1):通过矩阵吸收十倍提速 MLA
算子](https://zhuanlan.zhihu.com/p/700214123)
- [3][FlashInfer中DeepSeek MLA的内核设计](https://zhuanlan.zhihu.com/p/25920092499)