作者 formath 2024-01-23
点击率预估中的用户行为序列建模
背景
特征工程是CTR建模中最重要的问题。DNN时代之前,主要是人工构造组合特征和FM类自动交叉。迁移DNN初期,主要是FNN、PNN、DeppFM、Wide&Deep这类模型,特点是特征交互基本沿用了浅层模型的方法,区别是后接了MLP。此后,DNN在CTR领域站稳脚跟后,才开始真正的面向DNN,思考怎样进行特征交互建模,比如吸收了Attention等NLP领域的技术,这一阶段主要思考通用的特征交互方法。近几年,又开始面向某类特征,设计专用的特征交互方法,值得一提的是一系列用户行为序列建模的方法在工业界取得了非常大的收益。本文对用户行为序列建模做个概要的思路整理。
用户行为序列建模
从用户行为序列和Target Item做交互的粒度这个角度考虑,我把方案划分为以下几种:Element-Wise Interaction、Group-Wise Interaction、Interest-Wise Interaction。当然,也可以按其他维度划分。
Element-Wise Interaction
每个序列中的元素与Target Item进行交互,对序列中元素赋予不同权重然后根据权重进行Weighted Sum-Pooling,或者像RNN一样按时间顺序交互。
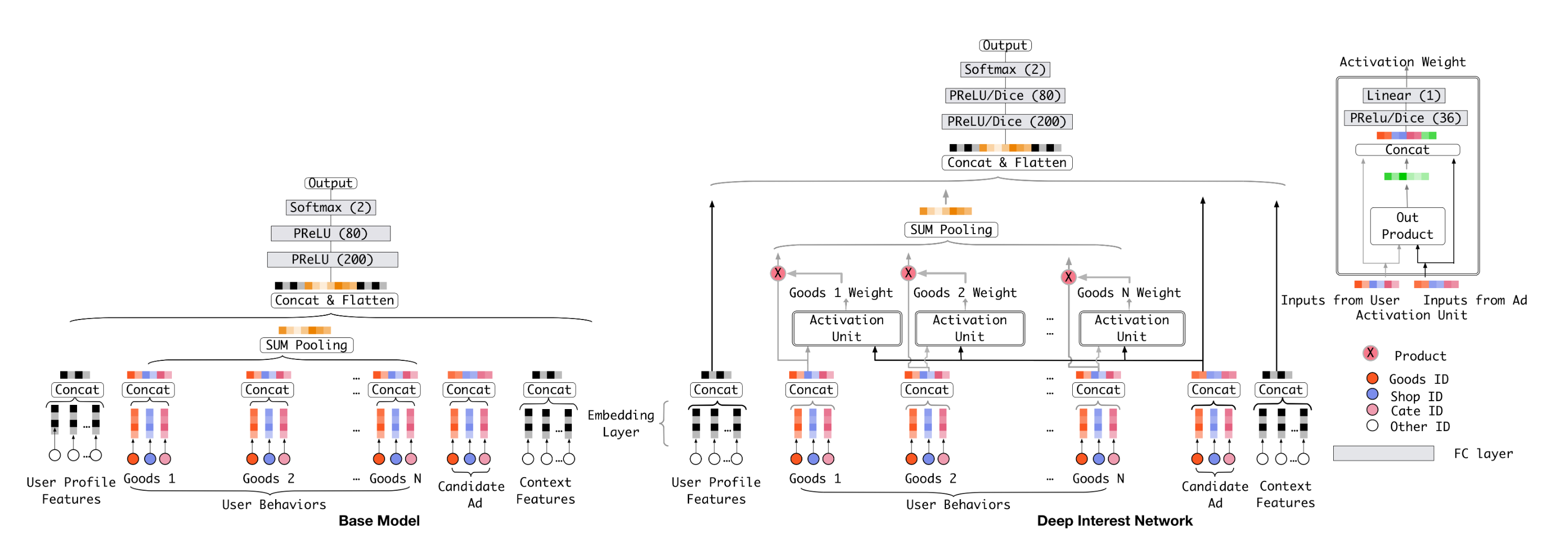
DIN
此前在DNN内使用序列特征大都是直接Pooling,阿里妈妈发的这篇Deep Interest Network1可以算是引领用户序列建模潮流的开山之作。论文出发点是序列里不同元素的权重不应该一样,与Target Item关系更近的应该赋予更大权重。权重通过外积接MLP得到,然后对序列进行Weighted Sum-Pooling。
DIEN & BST
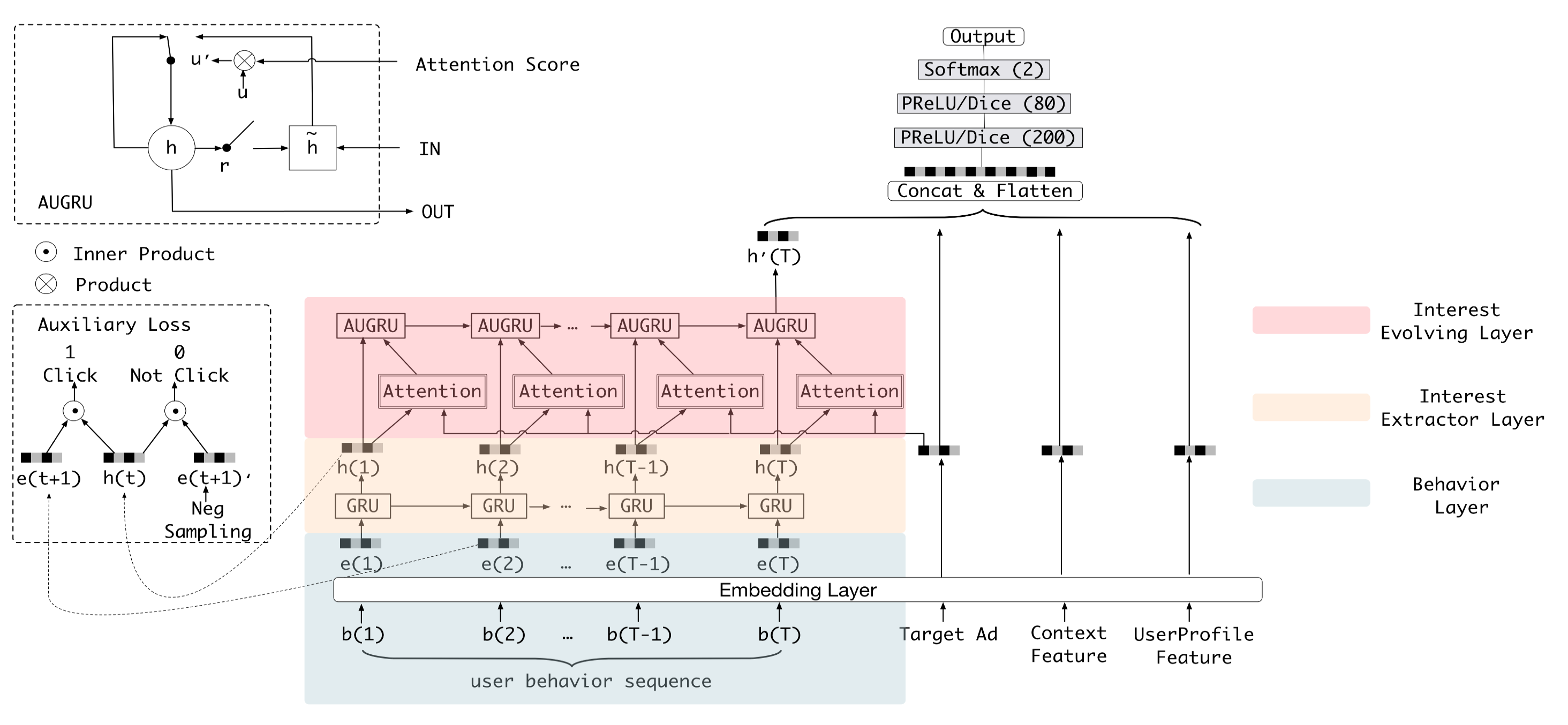
DIN没有考虑到行为序列内部的关系,如果考虑序列内部关系,一种是LSTM按顺序学习,另一种是使用Transformer做序列内部的Self-Attention。 对序列直接使用LSTM效果不好,因为用户行为随机性太强,没有NLP里那种词之间的语法关系模式。阿里妈妈的Deep Interest Evolution Network2,考虑了兴趣随时间的演变,设计了一个类似LSTM的复杂兴趣提取结构AUGRU,可以解决LSTM的问题,取时间序列最后一个Embeedding作为交互结果。不过这种按顺序的兴趣提取模型,在长序列上性能会是瓶颈,网络结构也比较复杂,在业界不太流行。在我看来,DNN的大部分结构还是比较符合直觉的,比如Attention甚至更复杂Transformer。但我第一次看LSTM结构时,就被那巧妙设计震惊了,一直很想了解这么复杂的玩意背后的设计过程,它不是那么符合直觉,需要细细的去理解各个门的设计以及电路图似的组合。不太符合直觉的东西,就不太想去用,DIEN文章里提出的AUGRU结构就是这种。
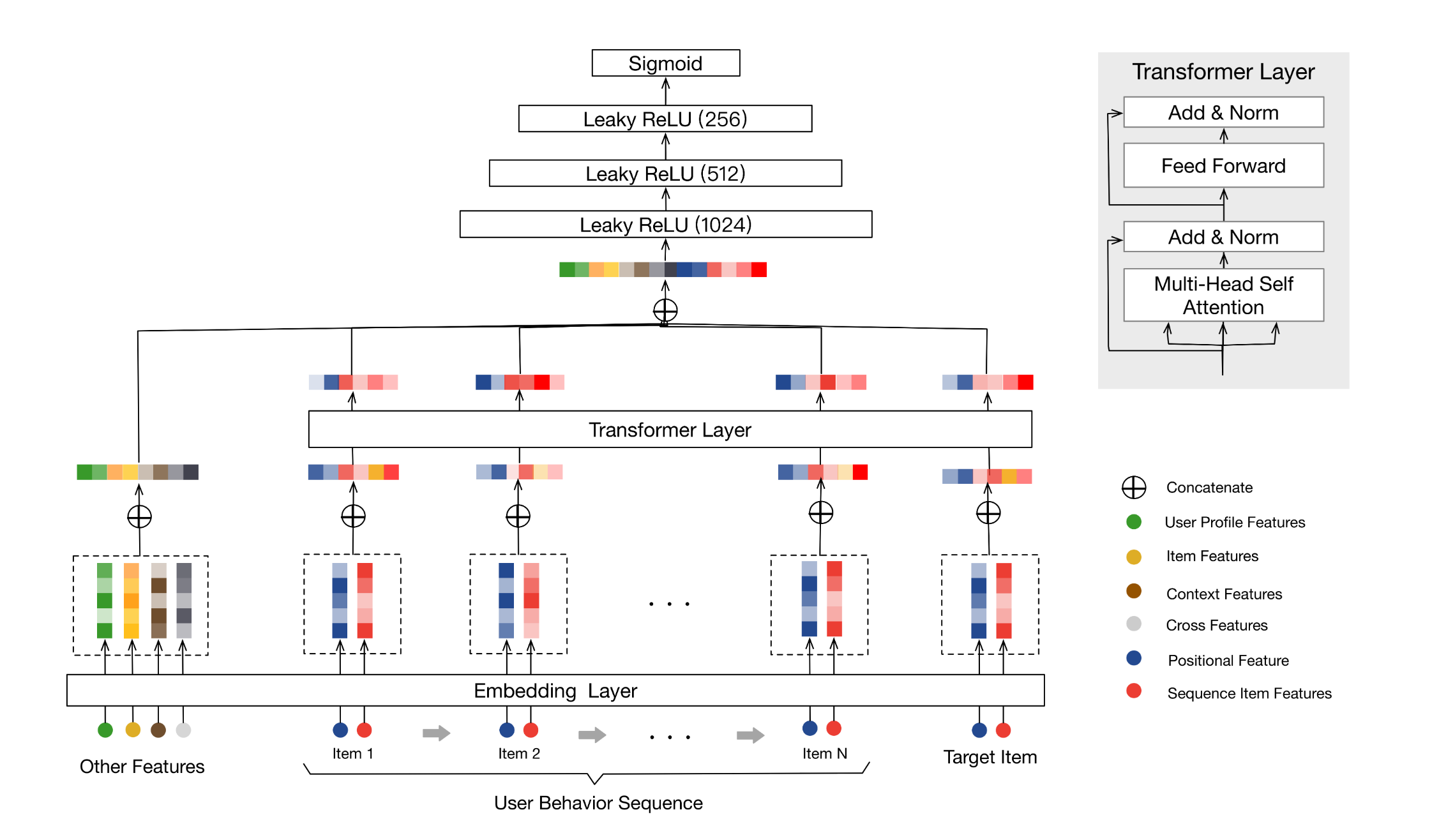
类似的工作还有Behavior Sequence Transformer8,使用Transformer先得到Sequence-aware的Item Embedding,再把Sequence Item Embedding和Target Embedding以及其他特征拼起来过MLP。BST发表时DIN已经提出了,所以这里应该用Sequence Item Embedding与Target Embedding做下Attention交互会更合适,感觉这个工作不是太完整。
SIM
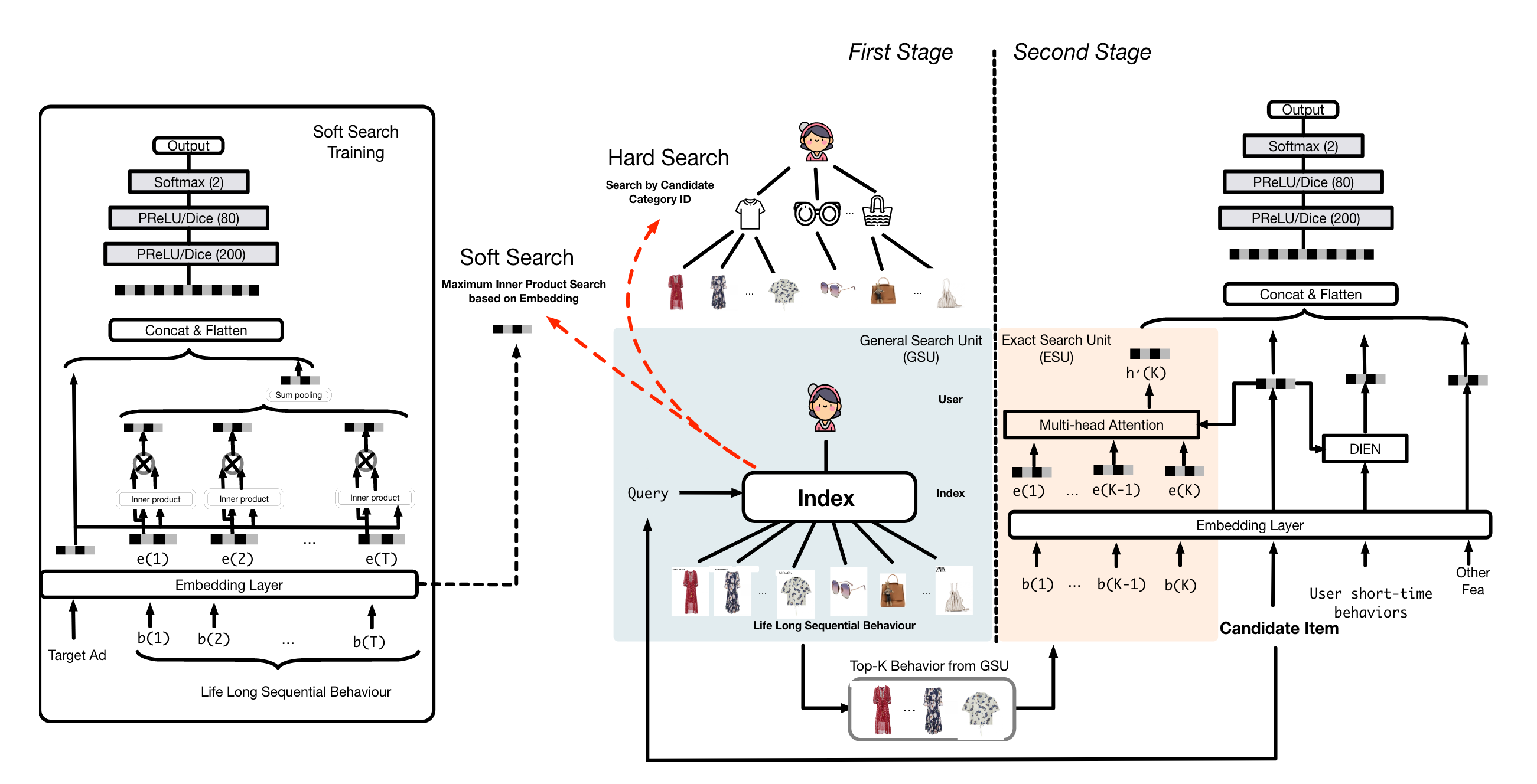
Element-Wise Interaction的主要问题是,如果序列非常大,每个元素都与Target Item交互的话,性能是个瓶颈,比如DIN只能处理一两百的序列长度。阿里妈妈的Search-based Interest Model3提出了两阶段方法,第一阶段根据Target Item信息从超长序列中检索出一个短的子序列,第二阶段使用短序列与Target Item做交互。 主要创新点在第一阶段,提出了Hard-Search和Soft-Search,前者根据Target Item的类目或其他属性作为Query去检索子序列,后者使用Embedding做ANN近似检索。论文中指出,Soft-Search的Embedding不可以使用短序列训练出来的,因为短序列和长序列的分布不一致,论文是通过长序列训练了一个辅助CTR模型得到的。截止目前SIM仍然是支持序列最长的方案,根据业界交流,Hard-Search使用更广泛,效果已经非常好了。第二阶段使用Multi-head Target Attention,计算Attention时,把序列Item发生时间与当前的时间差也离散化生成Embeeding拼接到了Item Embeeding上,相当于增加了时间bias,业界应用也会增加一些其他类型的bias特征。
ETA
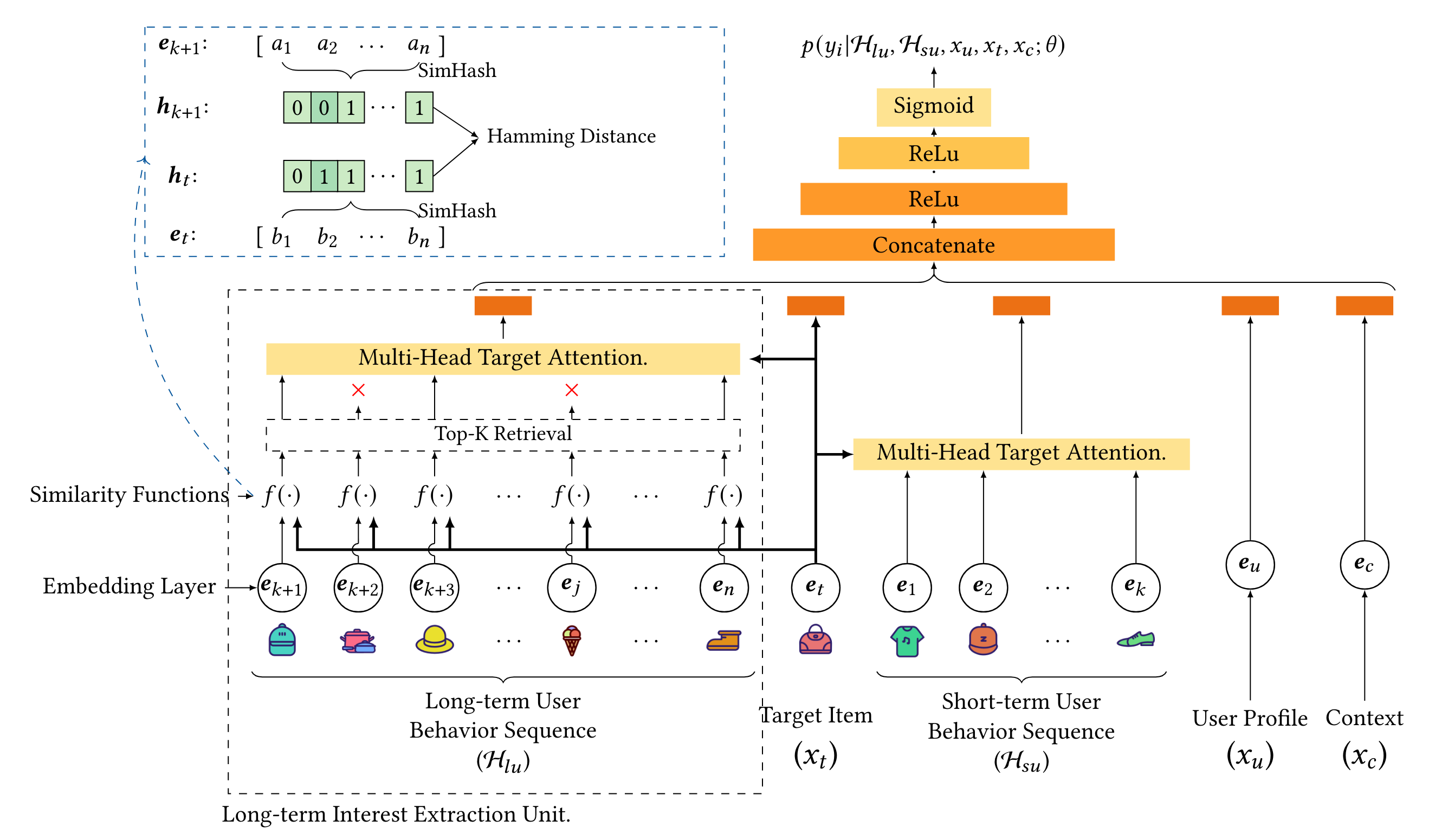
SIM的问题是第一阶段,检索逻辑和CTR主目标并不一致,会带来效果损失。阿里妈妈提出的Ene-to-End Target Attention4使端到端建模长序列成为可能,可以支持一两千的长序列(虽然还不如SIM长)。主要创新点是引入了SimHash,将Item Embedding映射成一个很小的Binary向量,Binary向量通过Hamming距离可以非常快的计算两个Item的相似度,按SimHash相似度取topK得到的子序列用于后续Multi-head Target Attention。SimHash过程相当于SIM第一阶段,不过检索速度更快,可以支持End-to-End训练了。Serving时Item的SimHash可以离线算好,线上直接按Hamming距离检索。虽然端到端训练了,但第一阶段用SimHash算相似度,与第二阶段的Target Attention其实还是不一致。
SDIM
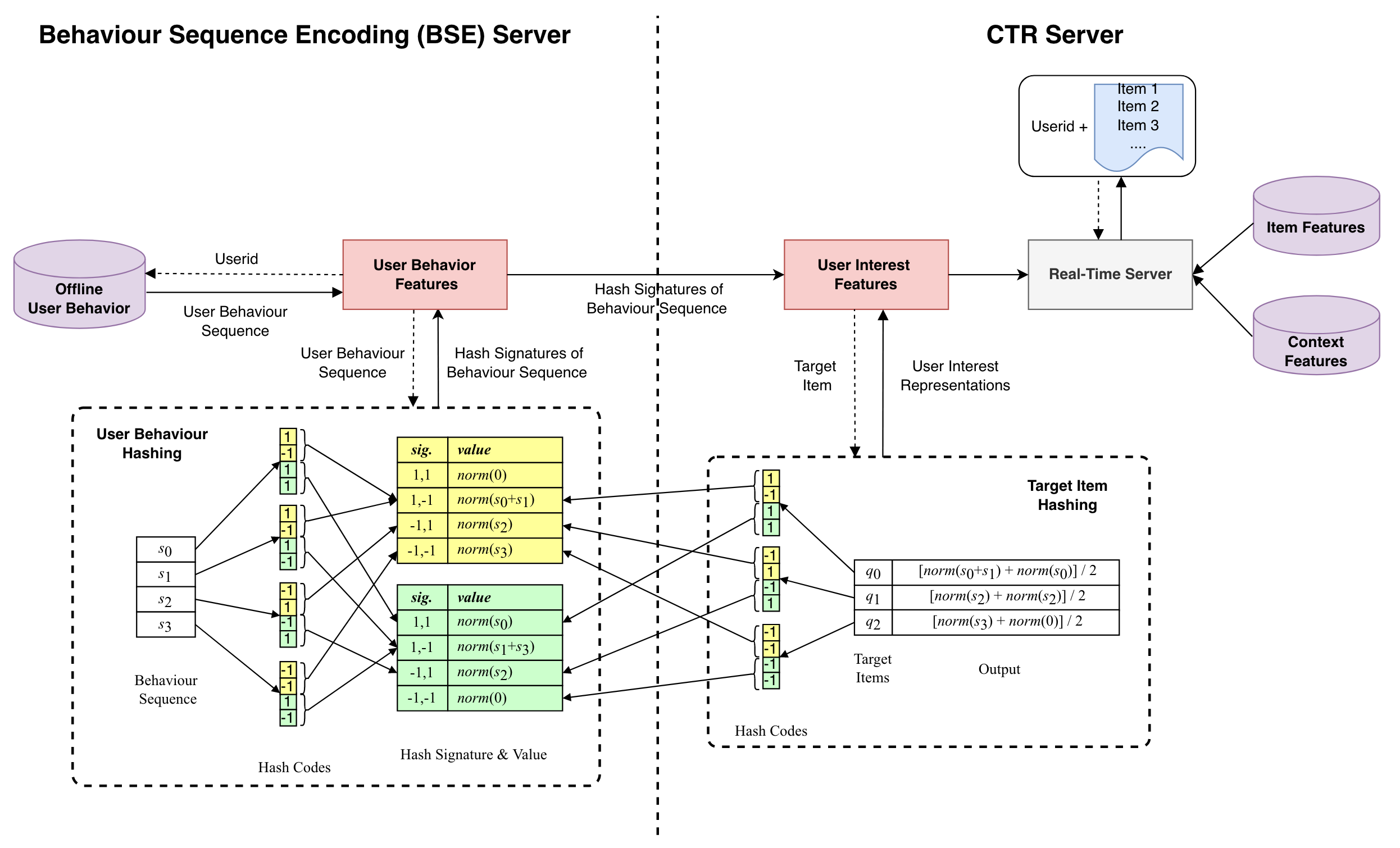
美团搜索提出的Sampling-based Deep Interest Modeling5进一步优化了ETA的性能。ETA检索出topK Item之后,然后做Pooling(不考虑Target Attention的话)。SDIM在离线得到Item SimHash后,把SimHash分成多片,每片把相应的全部Item Embedding做Pooling,然后写到Tair供线上查询,Tair里的key是分片Binary,value是Pooling结果,所以存储大小和Item的数量没关系了。检索时把Target Item的SimHash也分成多片,每片从Tair里检索Pooling后的Embedding,然后把检索结果再Pooling一次即可,检索量也和Item数量没关系了,检索和Pooling耗时基本可以忽略。从近似检索topK的原理上,SDIM其实不太准确,我感觉效果有效的原因可能是因为检索的更多了,稍有有点匹配的就检索回来了,不受topK的数量限制,虽然质量没那么强但数量可以弥补。
TWIN
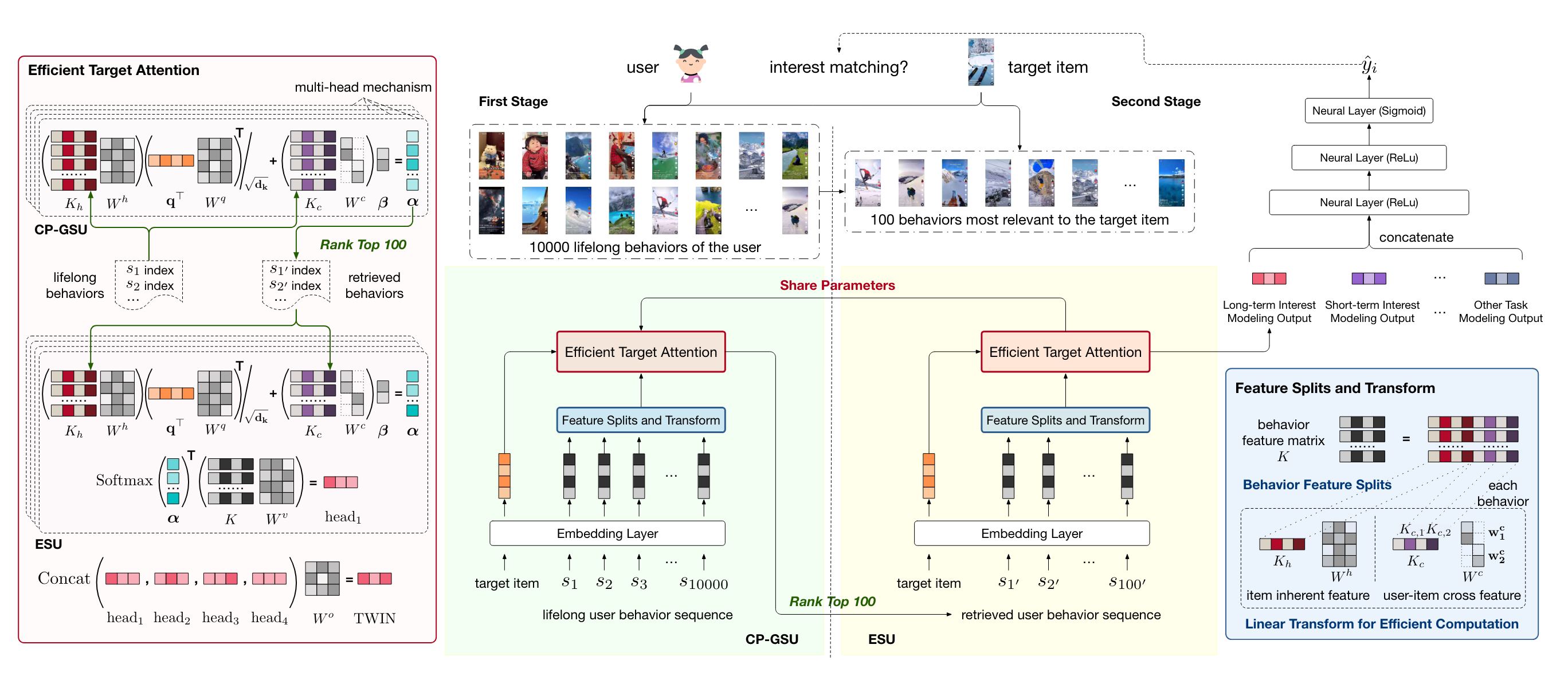
ETA虽然做到了端到端训练,但也没解决第一阶段的检索和第二阶段Attention匹配。快手提出的Two-stage Interest Network12,巧妙的优化了Multi-Head Target Attention计算效率,提出了Efficient Target Attention。第一阶段和第二阶段使用同一个Target Attention,保证了一二阶段的匹配。优化点是这样:用户行为序列里的Item特征,包含Item自身特征、以及User&Item交互特征,其中Item自身特征这部分在Attention里的中间结果可以缓存起来,放KV存储Serving时直接检索即可,而User&Item交互特征部分,降维到1,实时计算效率也很高。通过这两点优化,第一阶段的MHTA权重也可以在Serving时对全量序列实时计算了,选出topK给第二阶段。既然第一阶段的权重都计算好了,为什么还要选topK,直接在全量序列上Weighted Sum-Pooling不行吗?我认为其实是可以的,论文没这么做的出发点是这样:第一阶段缓存的中间参数更新没有那么及时,所以对全量序列得到的权重不是最新的,而第二阶段参数实时更新,可以算更准确的权重(我理解第二阶段的Sequence Item Embedding也是实时算)。
Group-Wise Interaction
将Element进一步聚合成Group,Group与Target Item进行交互。
DSIN
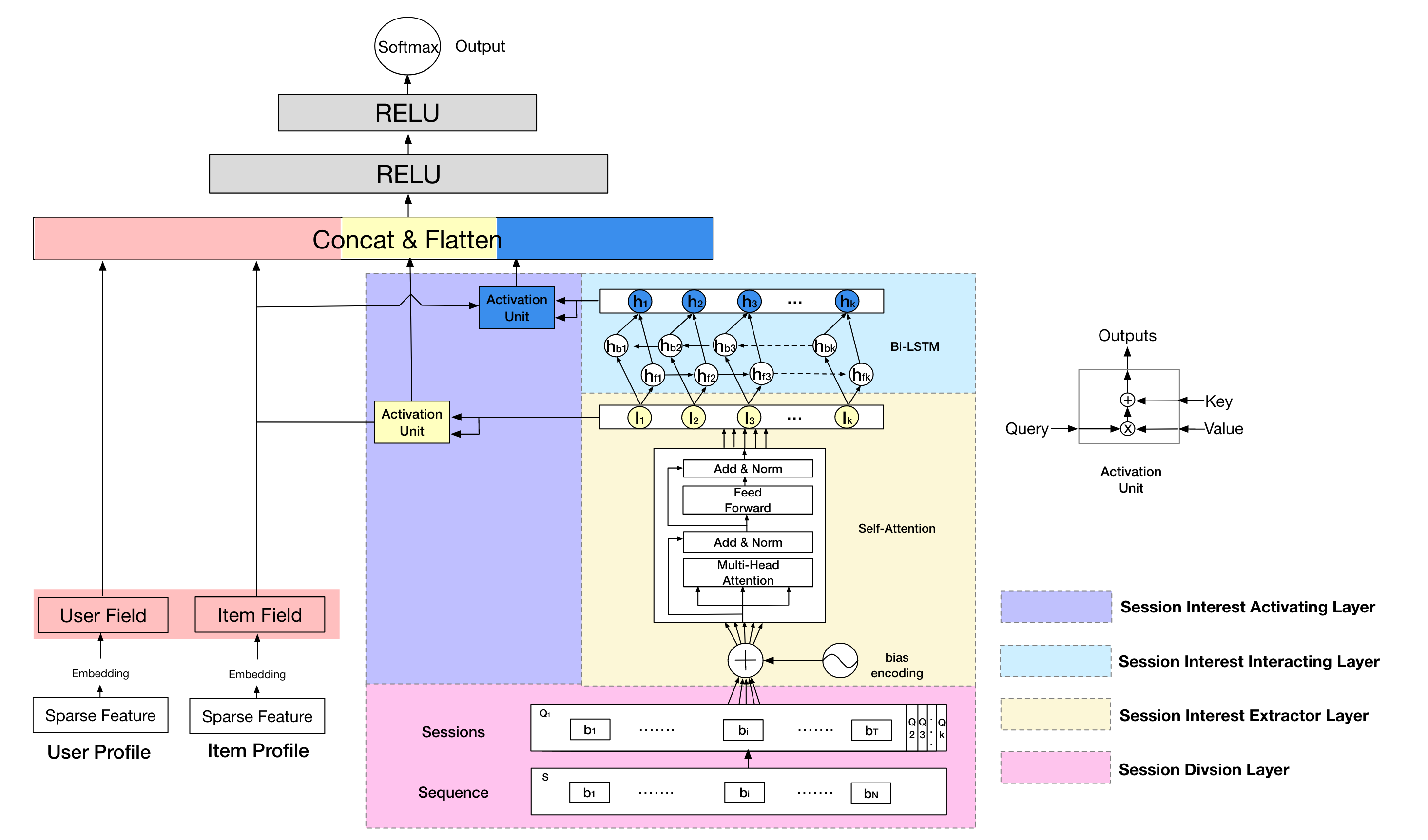
Session是按时间划分用户会话的方式,比如一般连续行为未超过30分钟算同一个Session。在搜索场景,Session内部行为很近似,Session间差异很大。根据这一特点,阿里妈妈提出的Deep Session Interest Network6,将序列划分成多个Session,每个Session内部先聚合形成一个Embedding,多个Session Embedding与Target Item进行交互。论文提取的Session Embeding生成方法比较复杂,据我了解,Session内简单Pooling就效果非常好。好像推荐用DSIN的不太多,可能Session这个特点在推荐不是太符合。
RACP
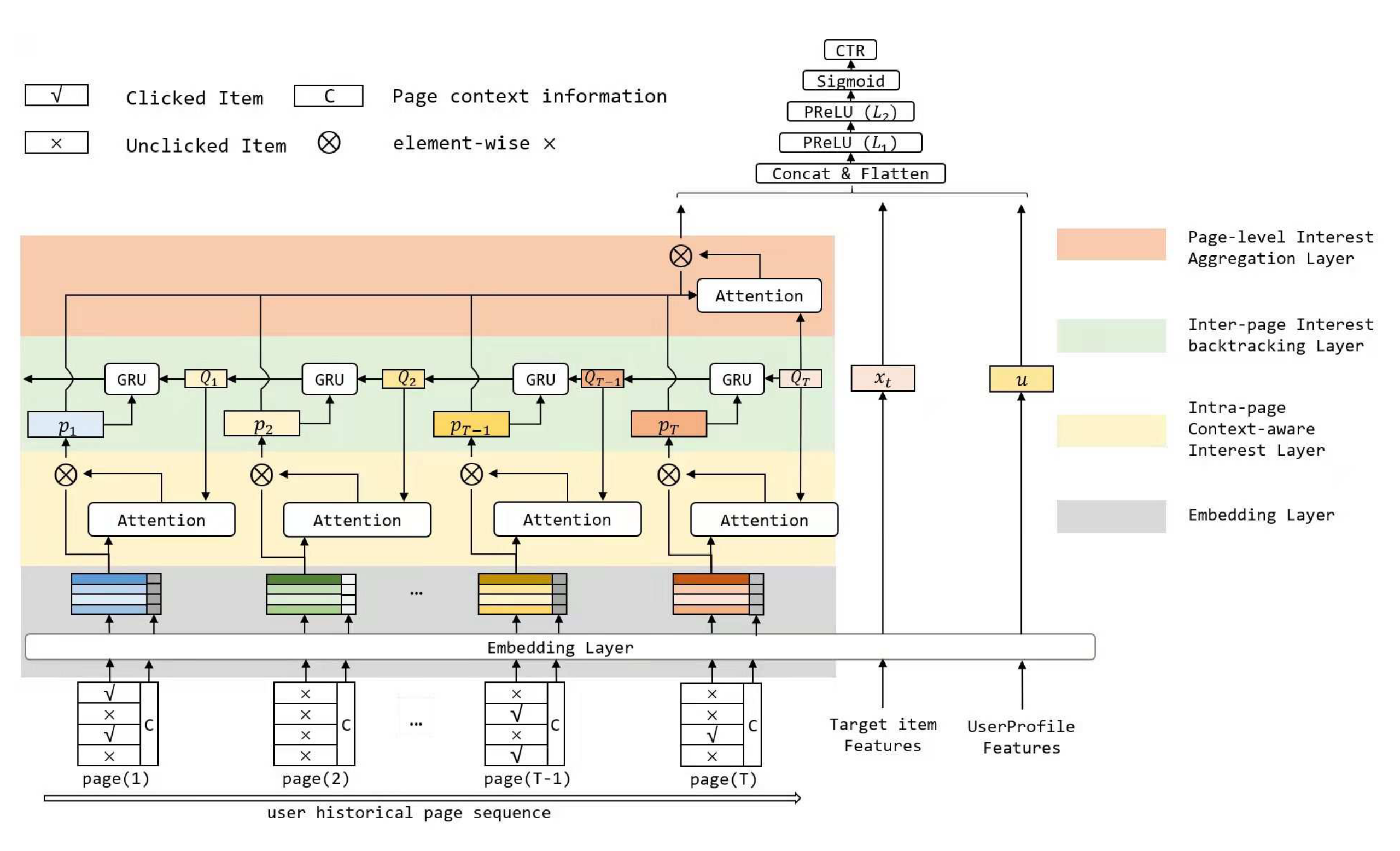
阿里提出的Recurrent Attention over Contextualized Page Sequence9,将序列元素按浏览页面Page进行聚合,每个Page内既有点击的也有曝光未点击item。Page先提取Embedding,然后Page Embedding通过类似DIEN的方式与Target Item做交互。Page考虑了元素的上下文信息,对行为刻画更充分。
Interest-Wise Interaction
先根据用户行为序列提取出Interest Embedding,再使用Interest Embedding与Target Item交互。
MIMN
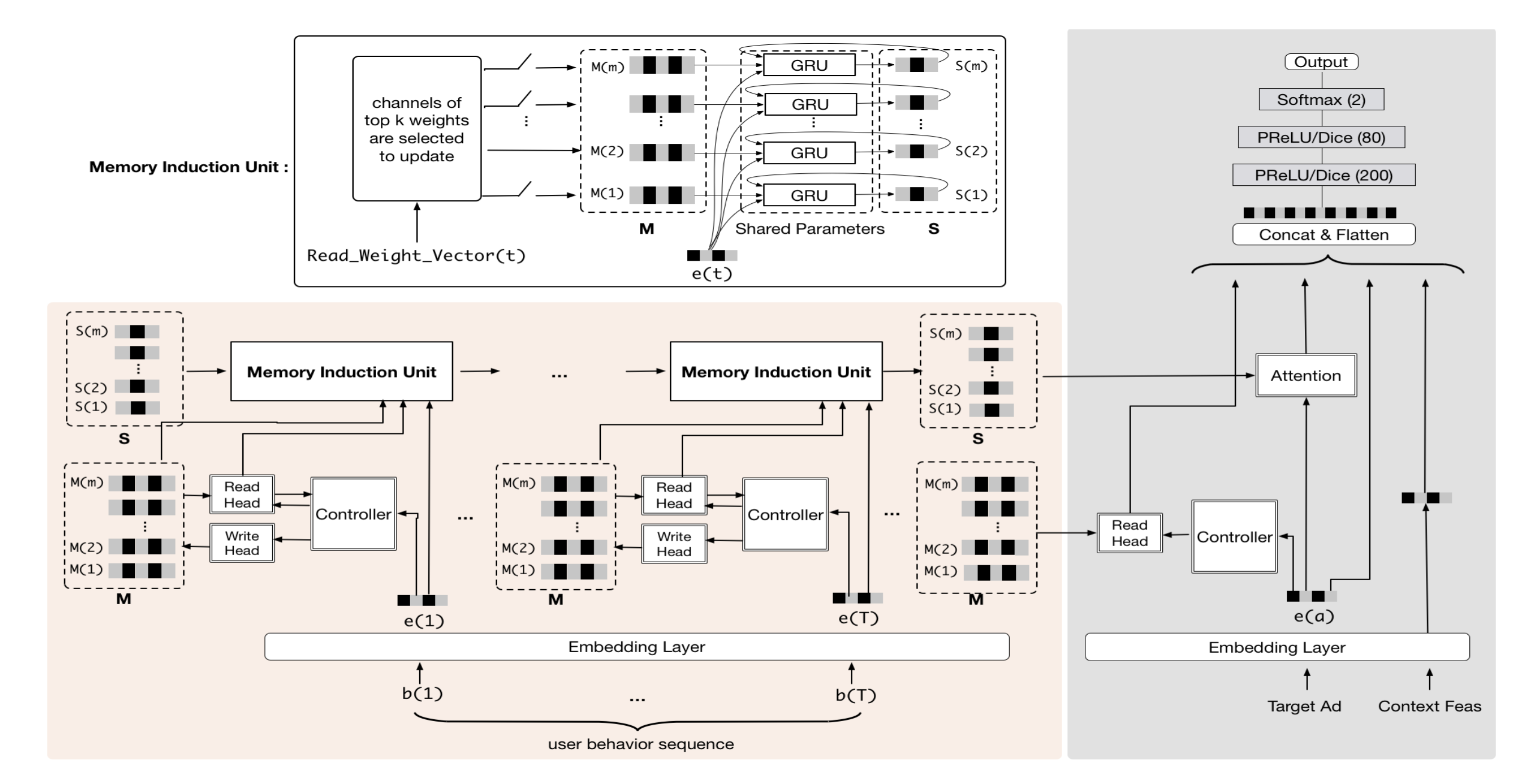
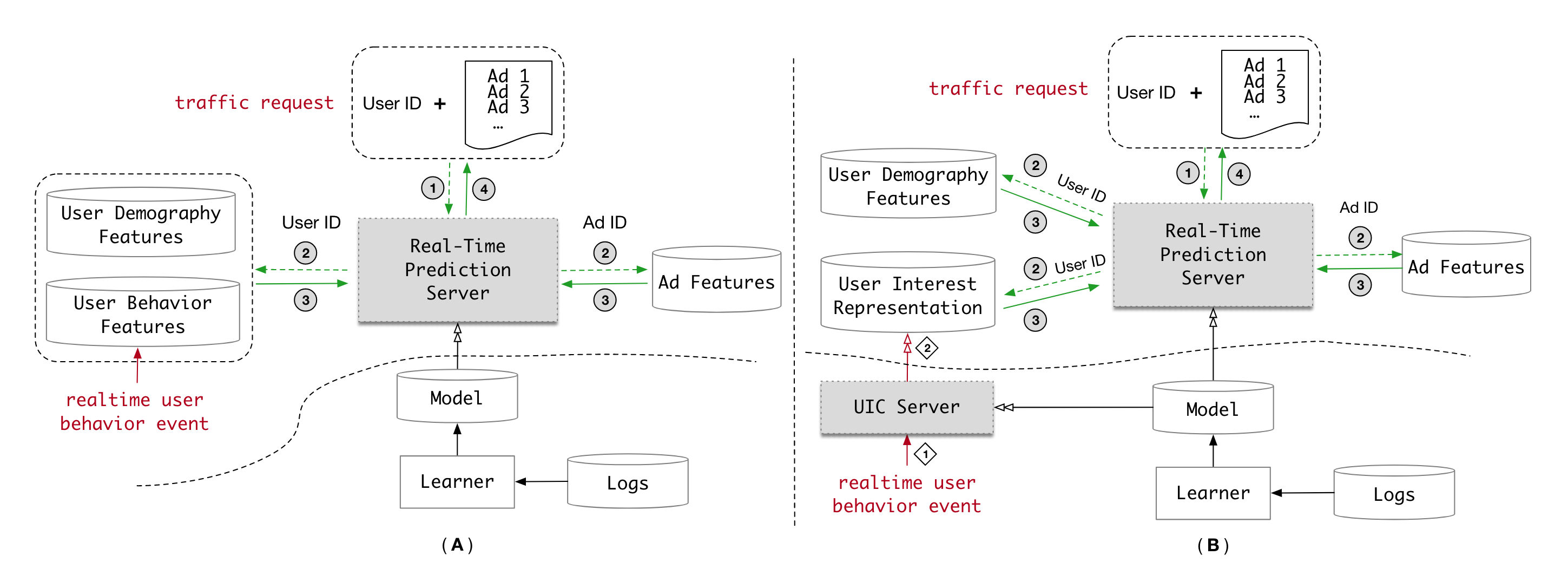
阿里妈妈提出的Multi-channel user Interest Memory Network7,也是针对长序列设计的。不过与SIM、ETA、SDIM、TWIN这些两阶段模型不同,MIMN针对长序列是端到端训练,但Serving时把长序列相关的部分单独拿出去部署。一般端到端训练也只能支持一两千的序列长度,所以比两阶段上万的序列还是短一些。MIMN的长序列兴趣提取部分与Target Item无关,根据长序列自身提取用户多个Interest Embedding,Interest Embedding预计算存入Tair供CTR模块使用。论文中长序列独立部署模块是实时接收用户行为,实时更新Tair里的向量。因为CTR主模块和长序列兴趣提取一起训练,但分开部署,所以模型更新时会有不一致,论文说即使长达一天的不一致对效果影响也不大,因为长序列的兴趣比较稳定,不会剧烈变化。美团广告其实也采用的这种长序列建模方法,不过兴趣向量是天级更新,时效性通过实时行为序列建模能弥补回来。对于兴趣怎么提取,Multi-Head Self Attention、Capsule都有广泛应用。MIMN里基于Neural Turing Machine,提出了一个更复杂的兴趣提取结构。另外,这类方法在抽取兴趣时和Target Item无关,所以在召回的双塔模型中用的也很普遍。
其他改进
序列拆分
拆成多个序列,每个序列可以应用不同的交互方式。
- 按时间拆分序列,比如分成Life-Long长序列和实时行为序列,甚至长序列再按周期拆分成多个子序列。
- 按场景拆分序列,比如拆分搜索行为和推荐行为序列、拆分图文推荐和视频推荐行为序列。
行为类型
业界对点击、收藏、转化这类行为序列建模比较普遍了,后续可以对更多序列数据进行建模,比如曝光序列、负反馈序列等,相关工作有腾讯的DFN10。
行为特征
序列元素的ID、类目等属性信息一般建模都使用了,序列元素发生时刻所处的Context特征用的还不是特别充分,相关工作有美团广告的DCIN11。
参考
- [1][Deep Interest Network for Click-Through Rate
Prediction](http://arxiv.org/abs/1706.06978)
- [2][Deep Interest Evolution Network for Click-Through Rate
Prediction](http://arxiv.org/abs/1809.03672)
- [3][Search-based User Interest Modeling with Lifelong Sequential
Behavior Data for Click-Through Rate
Prediction](http://arxiv.org/abs/2006.05639)
- [4][End-to-End User Behavior Retrieval in Click-Through
RatePrediction Model](http://arxiv.org/abs/2108.04468)
- [5][Sampling Is All You Need on Modeling Long-Term User Behaviors
for CTR Prediction](http://arxiv.org/abs/2205.10249)
- [6][Deep Session Interest Network for Click-Through Rate
Prediction](http://arxiv.org/abs/1905.06482)
- [7][Practice on Long Sequential User Behavior Modeling for
Click-Through Rate Prediction](http://arxiv.org/abs/1905.09248)
- [8][Behavior Sequence Transformer for E-commerce Recommendation in
Alibaba](http://arxiv.org/abs/1905.06874)
- [9][Modeling Users' Contextualized Page-wise Feedback for
Click-Through Rate Prediction in E-commerce
Search](http://arxiv.org/abs/2203.15542)
- [10][Deep Feedback Network for
Recommendation](https://www.ijcai.org/proceedings/2020/349)
- [11][Deep Context Interest Network for Click-Through Rate
Prediction](http://arxiv.org/abs/2308.06037)
- [12][TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou](http://arxiv.org/abs/2302.02352)