作者 formath 2026-01-28
调研一下排序模型的Scaling Law
背景
排序模型的Scaling Law,基本都是token化后,然后接transformer/residual类结构,形成以下几个scaling方向:
- token序列长度来实现模型输入scaling
- residual堆叠来实现模型深度方向scaling
- residual层内维度来实现模型宽度方向scaling
本文对业界方案进行调研总结。
特征交叉的Scaling Law
这部分方法中,序列特征先用常规方式(target attention、pooling等)进行压缩,再和其他的非序列特征一起进行多层交叉。当然,不是说必须先把序列压缩,序列和非序列统一做交叉也可以,只是思路出发点不同。
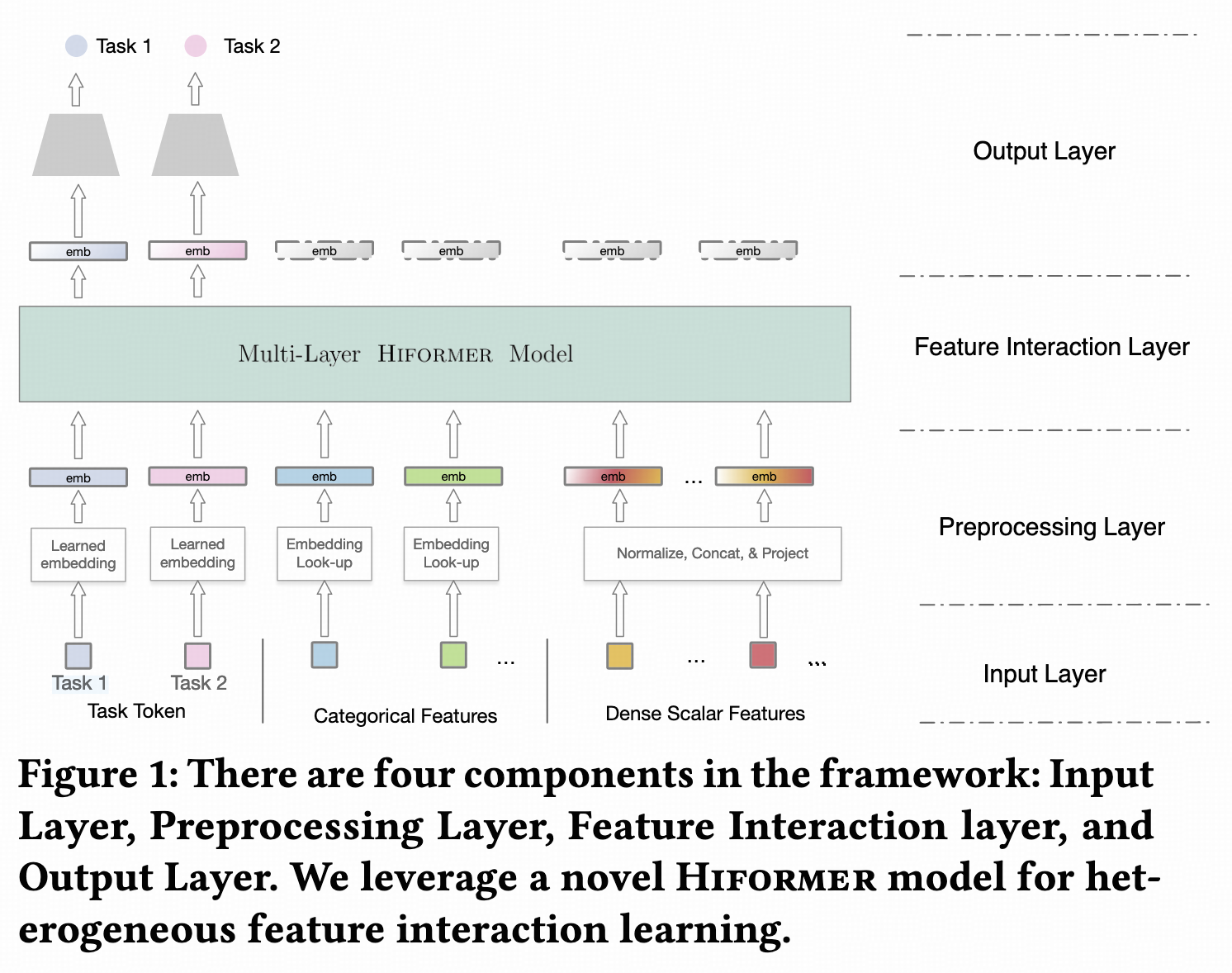
HeteroAtt & Hiformer
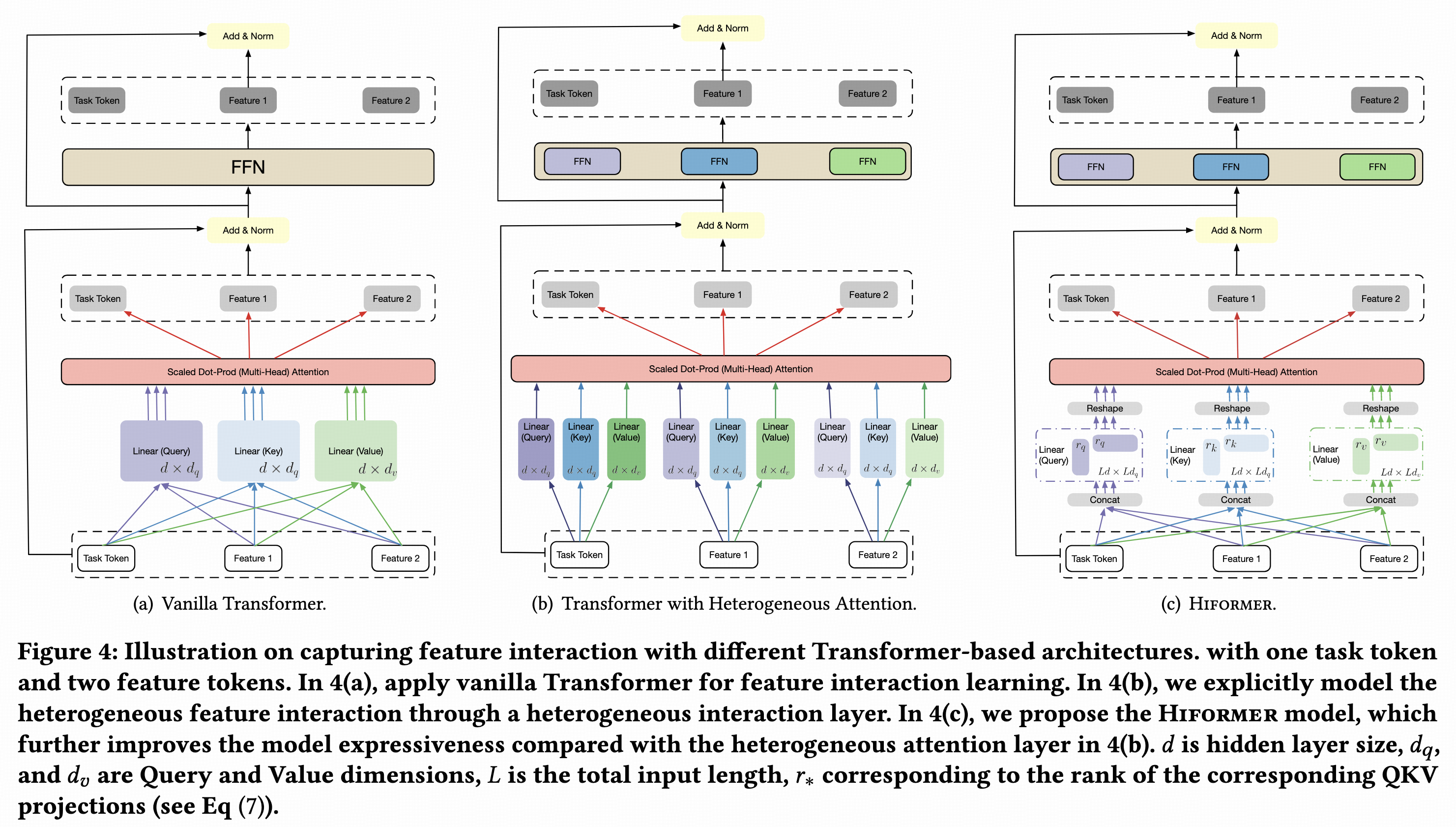
经典的Transformer结构中,所有token共享Q、K、V、O、FFN参数,但在搜广推领域,特征是异构的。Google
Play在论文1中提出异构attention结构(HeteroAtt),每个特征具有独立的Q、K、V、O、FFN参数。假如有T个token,参数量翻T倍但计算量不变。为了进一步交叉,在HeteroAtt的基础上提出Hiformer。以Q为例,HeteroAtt的Q是[Dt, Dk]维,输入是[B, Dt]维,通过Q变换为[B, Dk]维,其中Dt是token维度,Dk是attention
query维度,B是batch
size。而Hiformer的Q是[T * Dt, T * Dk]维,输入是[B, T * Dt]维,通过Q变换为[B, T * Dk]维,然后再split成T个token
query,其中T是序列长度。K和V同理。
Transformer multi-head attention的参数量是Q为例,将[T * Dt, T * Dk]维变为两个Lora矩阵,分别是[T * Dt, Dk_lora]维和[Dk_lora, T * Dk]维。Lora之后,Hiformer的参数量变为
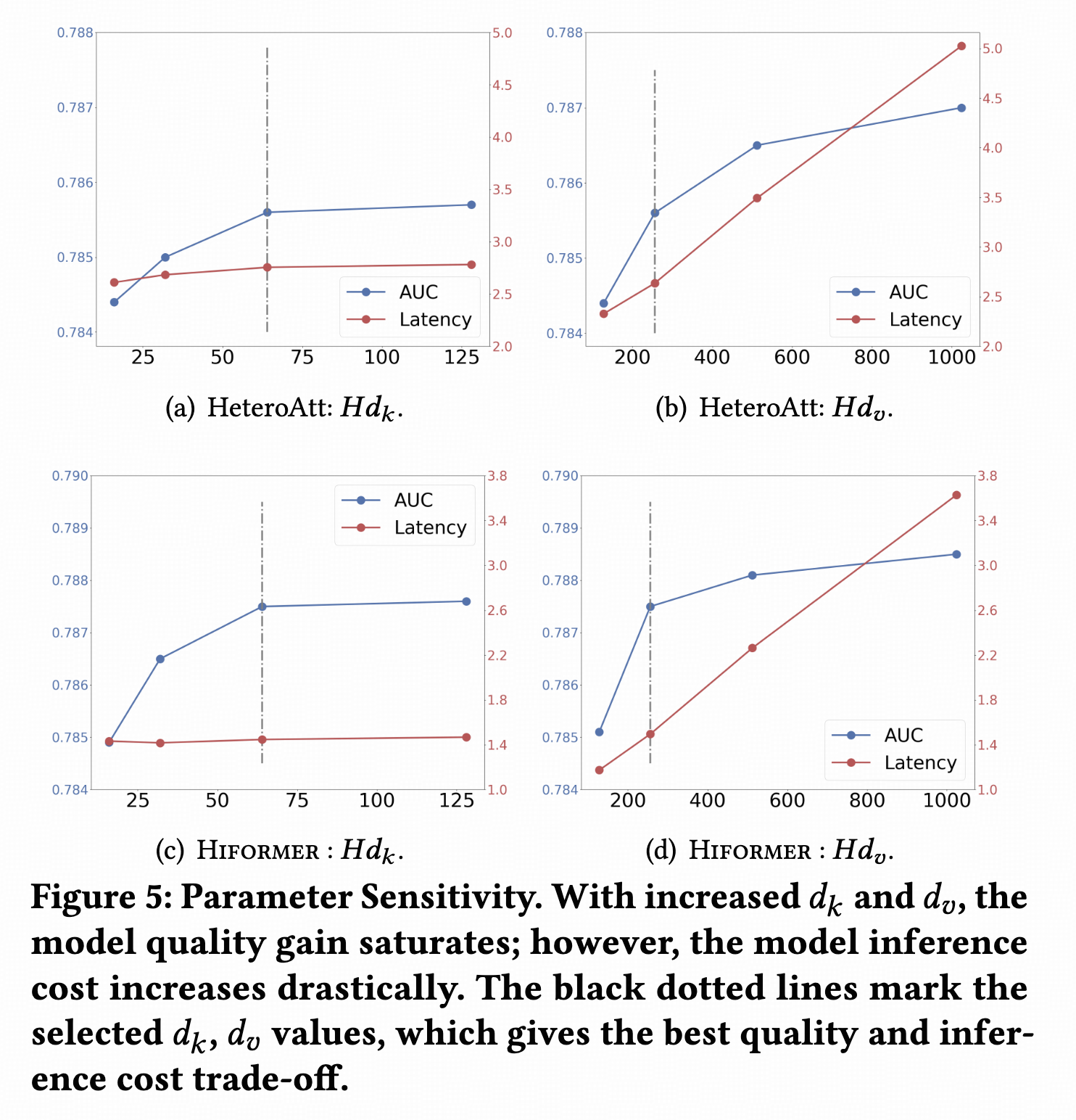
scaling效果有但不是非常显著。
HHFT
淘宝搜索在论文2中提出的,将上面介绍的HeteroAtt和Hiformer做了堆叠,先堆n1层HeteroAtt,再堆n2层Hiformer,这么做的动机在论文里没提。
Token是特征group粒度的,先将特征划分成多个group,每个group内所有特征emb concat后过一个group独立的单层mlp后得到token。
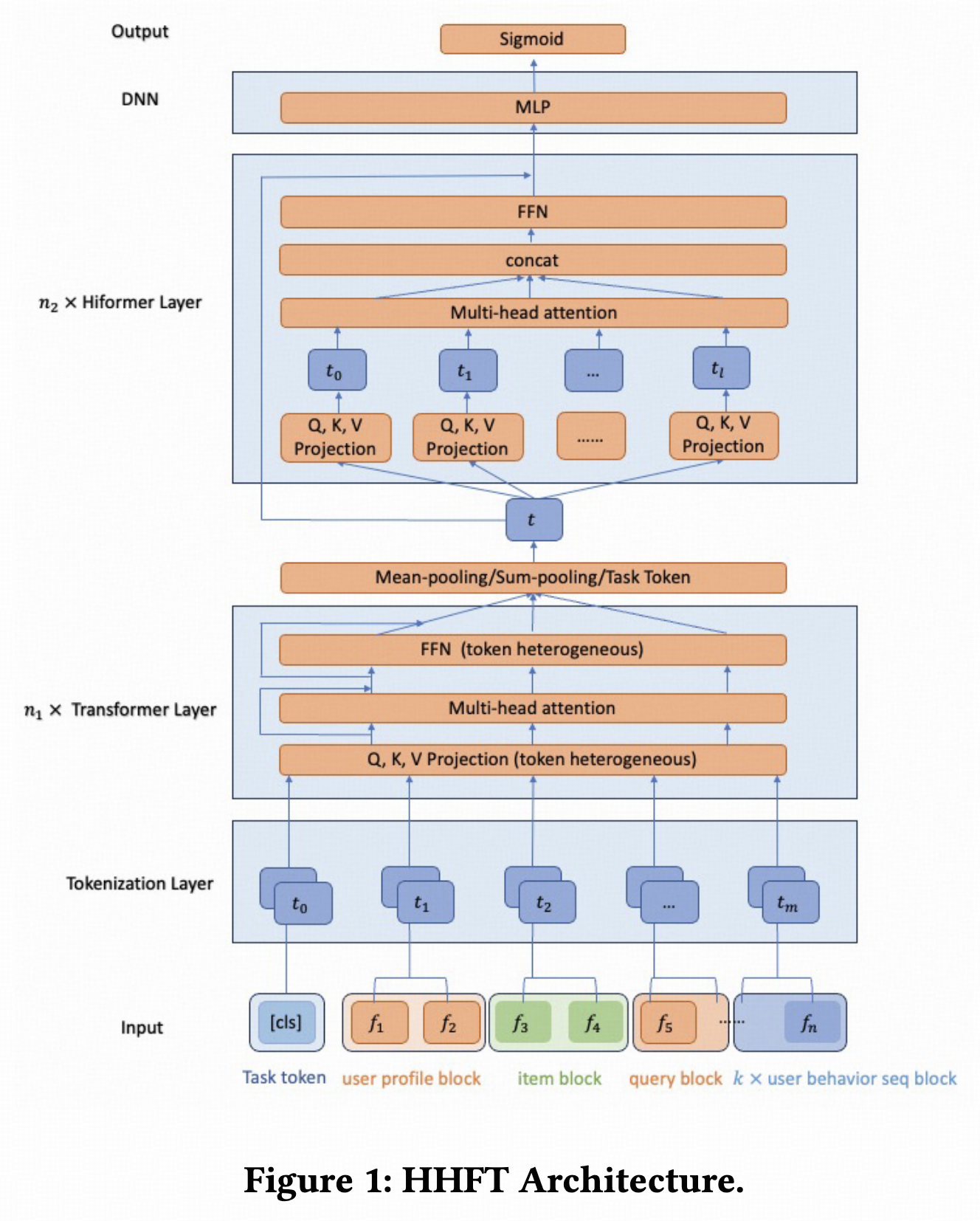
Scaling效果方面,提升dim维度比提升层数效果更明显,提升Hiformer参数量比提升HeteroAtt的参数量效果更明显。
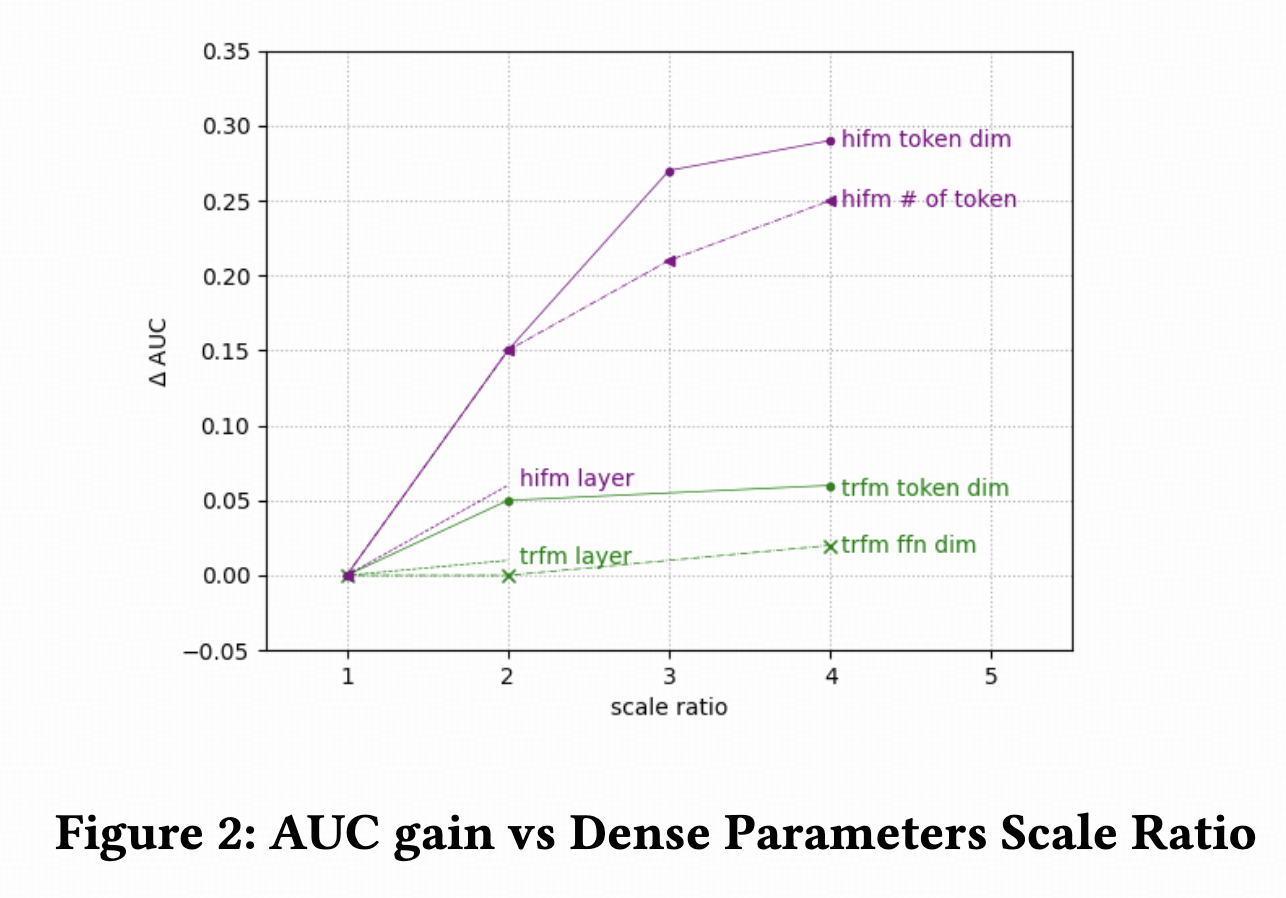
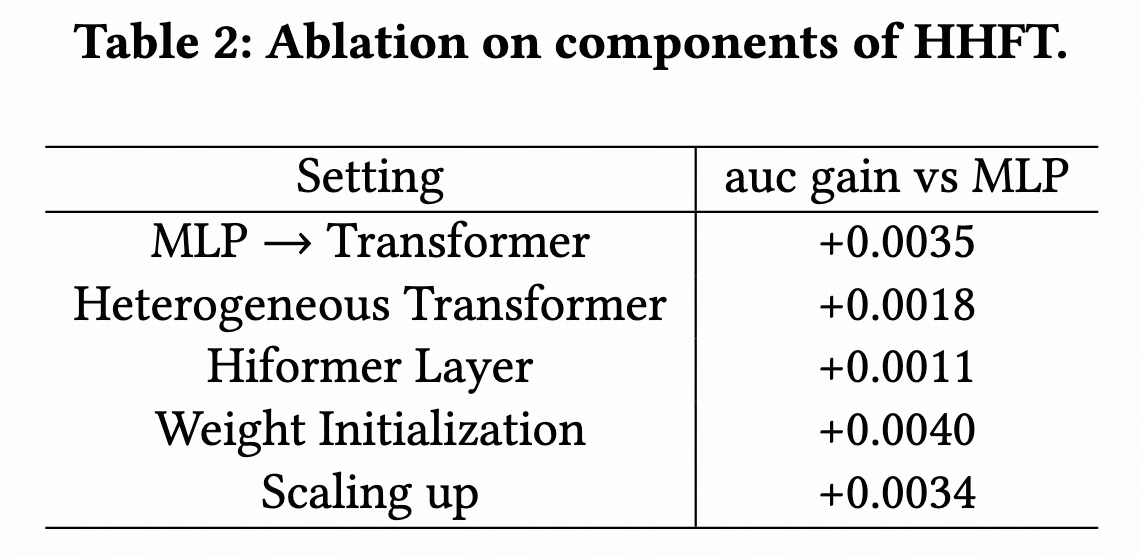
另外,模型消融,效果最明显的是一些trick而不是模型结构。这个我也有同感,transformer类的模型,在参数初始化、学习率warmup&decay、norm方式和位置等方面需要细调,如果设置不好效果反而比简单模型差,特别是scaling之后更这些设置影响更大。
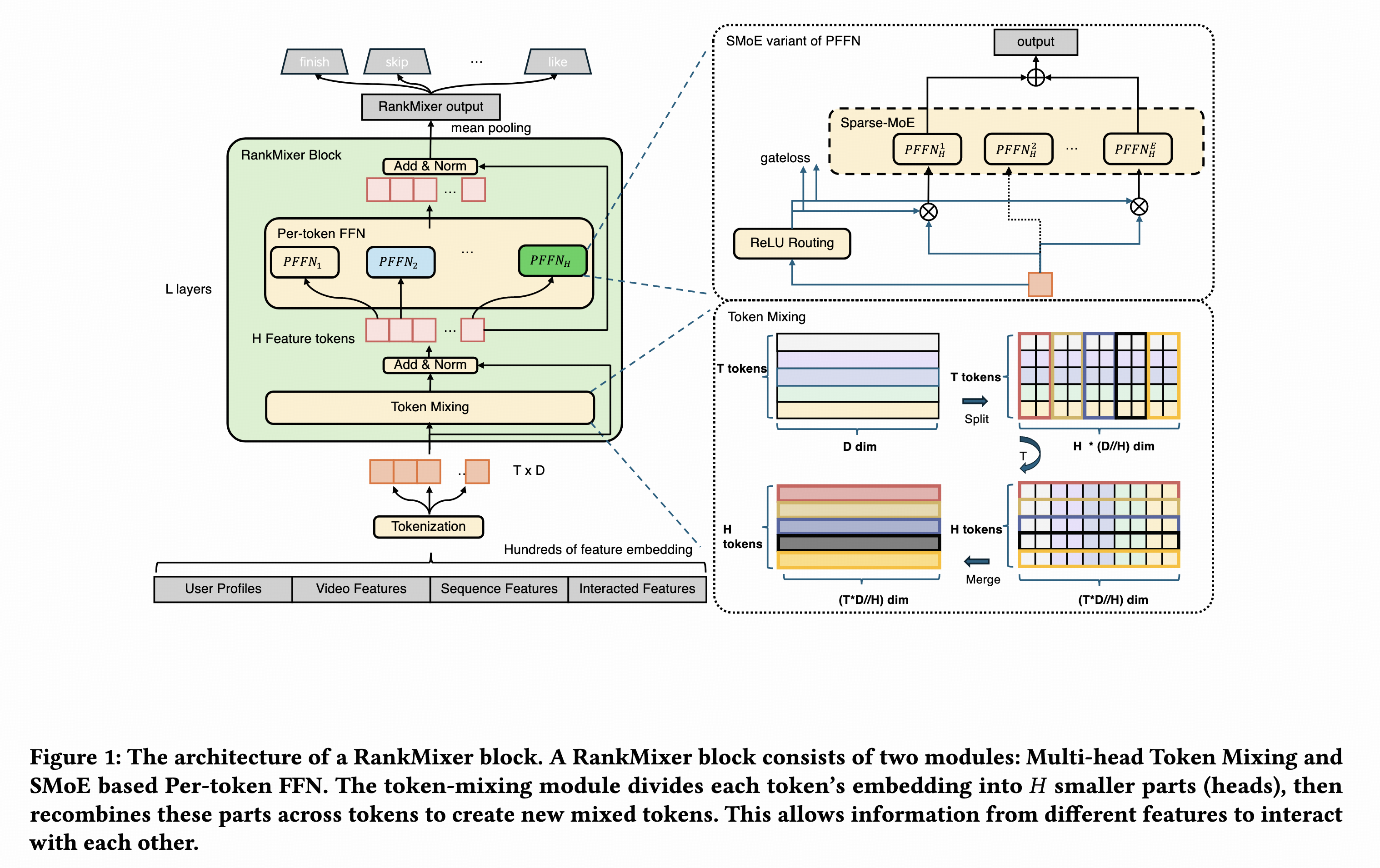
RankMixer
抖音推荐和广告在论文3中提出,主要是用一个无参数的简单操作替换了mha,将原始输入做下转置,再和原始输入直接相加即可,后面的ffn采用每个token独立的参数。Token也是group粒度的。
# 输入 |
模型结构如下,其中的sparse moe从效果角度来说感觉不用太关注,主要是sparse moe太火了,蹭一下讲故事更好听。
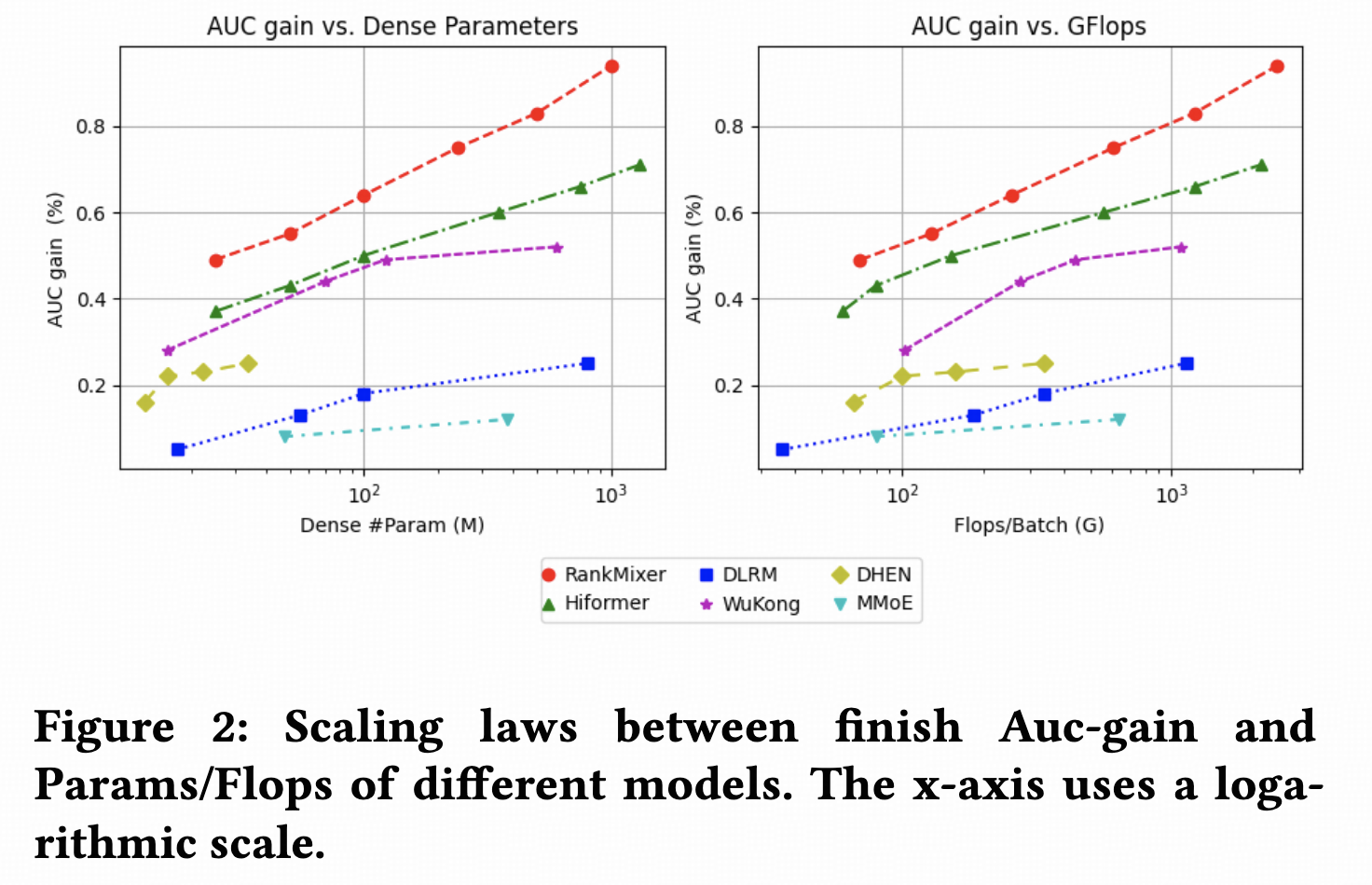
Scaling效果非常显著,但细节方面提的不多,只说T、D、L不同方面进行scaling都有近似的效果。我也尝试过,scale D效果最好。
序列和非序列统一建模的Scaling Law
针对序列和非序列统一建模进行了一些设计,序列不用先压缩,序列和非序列平铺成token序列,再多层交叉。
HSTU
Meta在论文8提出的,掀起了生成式推荐的热潮,不过严格来说排序这块还是判别式的。
特征组织方面,将序列特征和非序列特征都token化,通过casual attention来控制token间的交互关系。
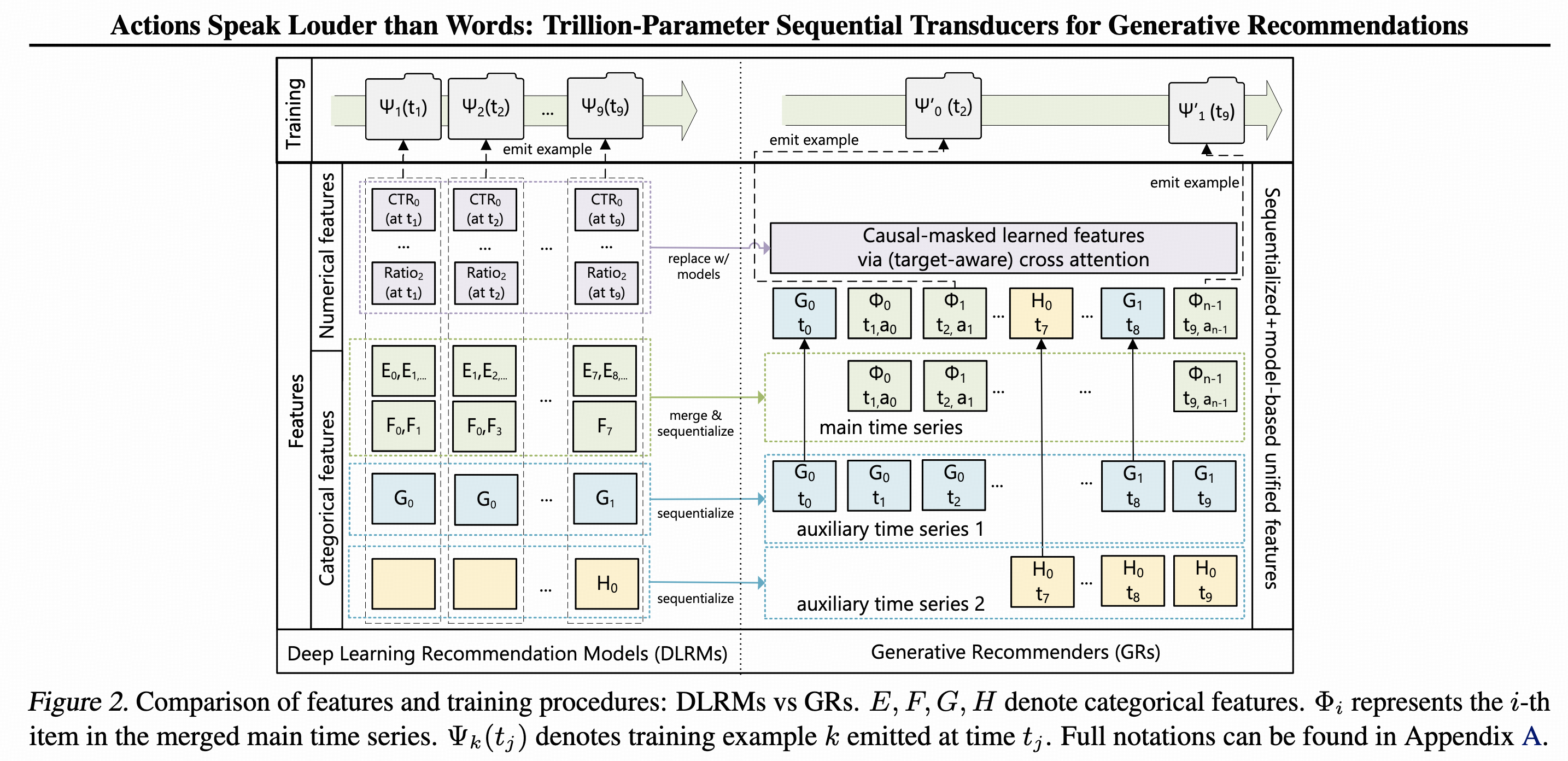
模型层面,没有采用经典transformer结构,而是设计了全新的HSTU,其中attention方式和mha差别较大。多层交叉后,使用曝光item的token hidden emb,后接一个多目标网络进行打分。
数据按请求粒度进行了聚合,降低用户序列部分的重复计算。
对用户行为序列的token进行了dropout,最长训到8192长度。
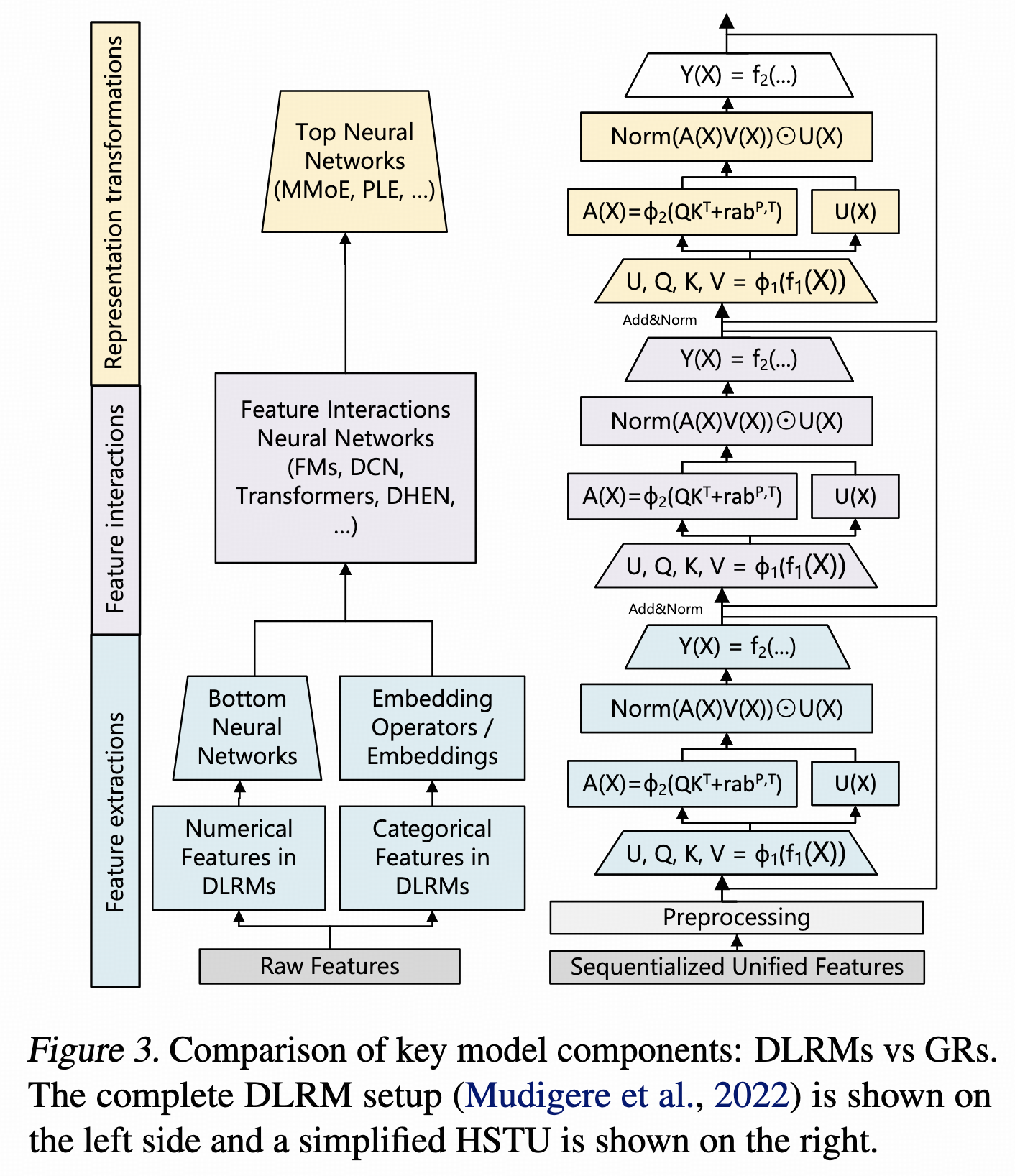
HSTU首次观测到了推荐模型的Scaling Law现象,掀起了搜广推领域的Scaling热潮。工程方面也做了很多优化,后续其他公司的很多方案都在借鉴,这篇论文值得精读。
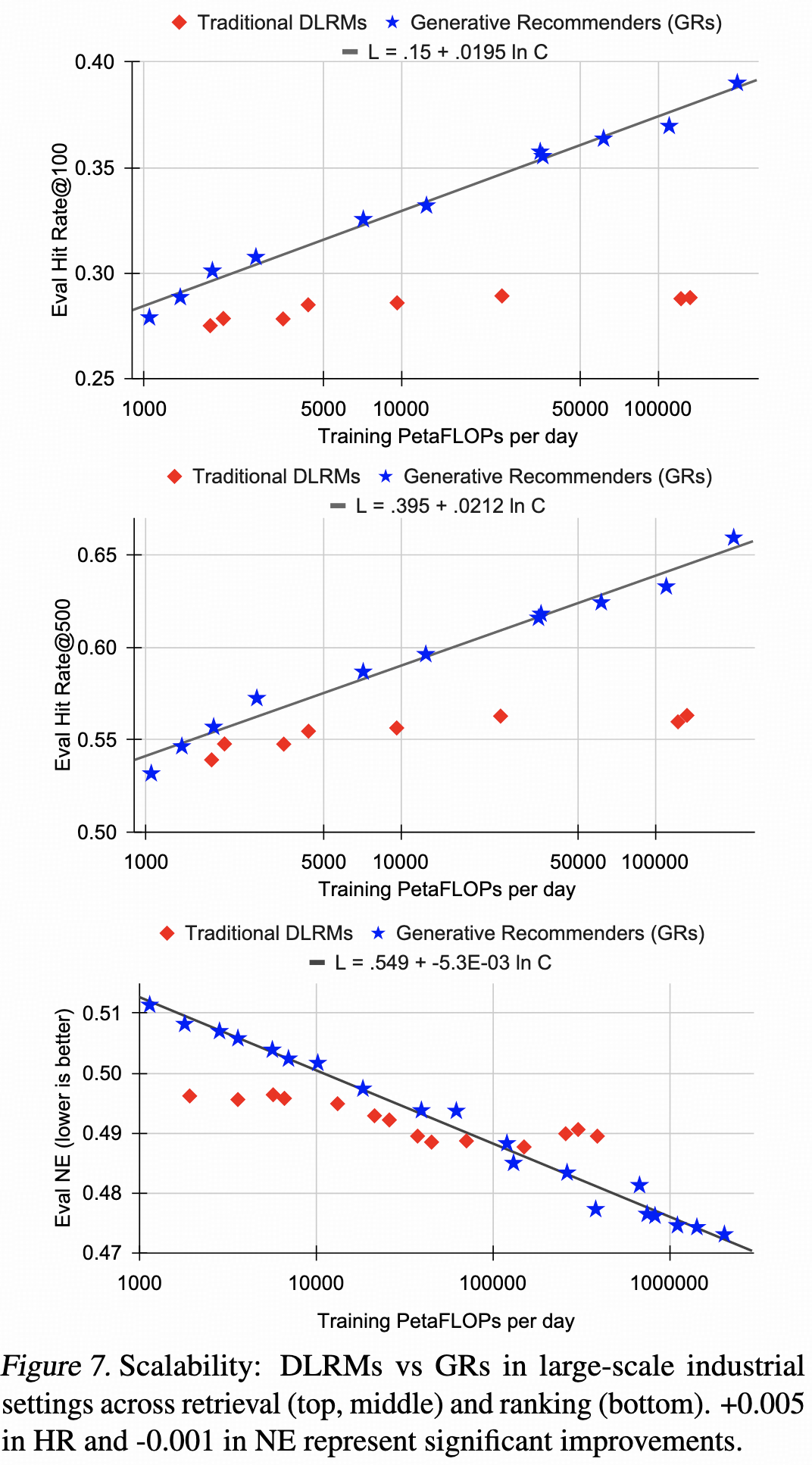
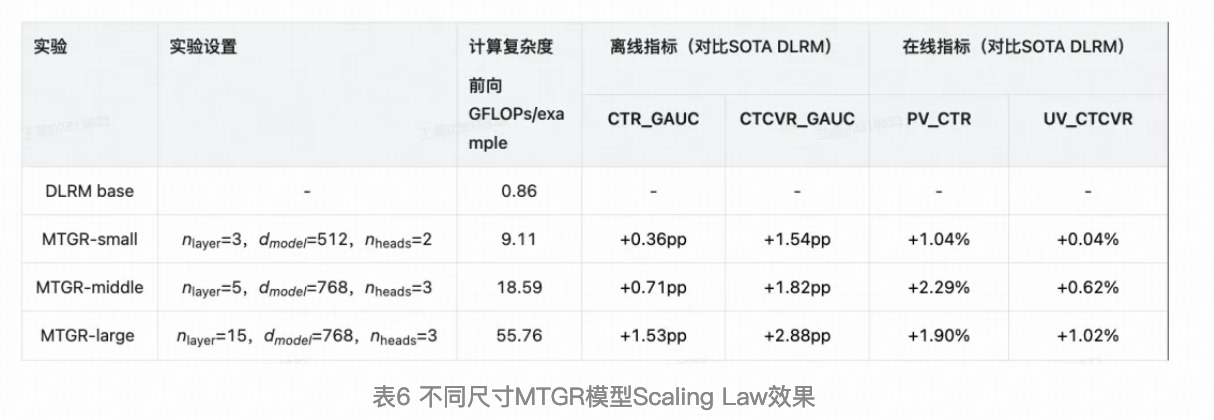
MTGR
美团外卖推荐的方案6,结构和Meta HSTU差不多。
天级将用户曝光聚合成一条样本。
行为序列特征token化:每个行为,将item id emb和side-info emb concat后映射成一个token;
user侧非序列特征token化:每个特征生成一个token;
曝光item token化:将item id、side-info、交叉特征、context特征等concat后映射成一个token。
基础结构是HSTU,其中采用casual attention。
这里有个问题: 将用户曝光天级聚合后,每个用户对应一条样本,user侧特征只能训练一次。那么在训练初期,由于nn还没收敛,先训练的这些用户对应的user侧特征sparse emb可能学习的不够充分,和最终要收敛的nn不匹配。而曝光粒度样本,由于随机shuffle,user侧特征在每个训练阶段都能学习到,就不存在这种问题。
如果是纯流式训练只能按request粒度或短期内user粒度聚合,影响不大。如果是【T+1天级训练 -> 天内分钟级流式训练】这种模式,其中的天级训练需要考虑样本粒度问题,可以像Meta HSTU一样进行request粒度聚合,或者尝试下面百度GRAB的方案。
另外,很多训推性能优化的细节值得学习。
Scaling效果,在D、L方向上效果显著。
GRAB
百度推荐广告的方案7,结构也和Meta HSTU差不多。
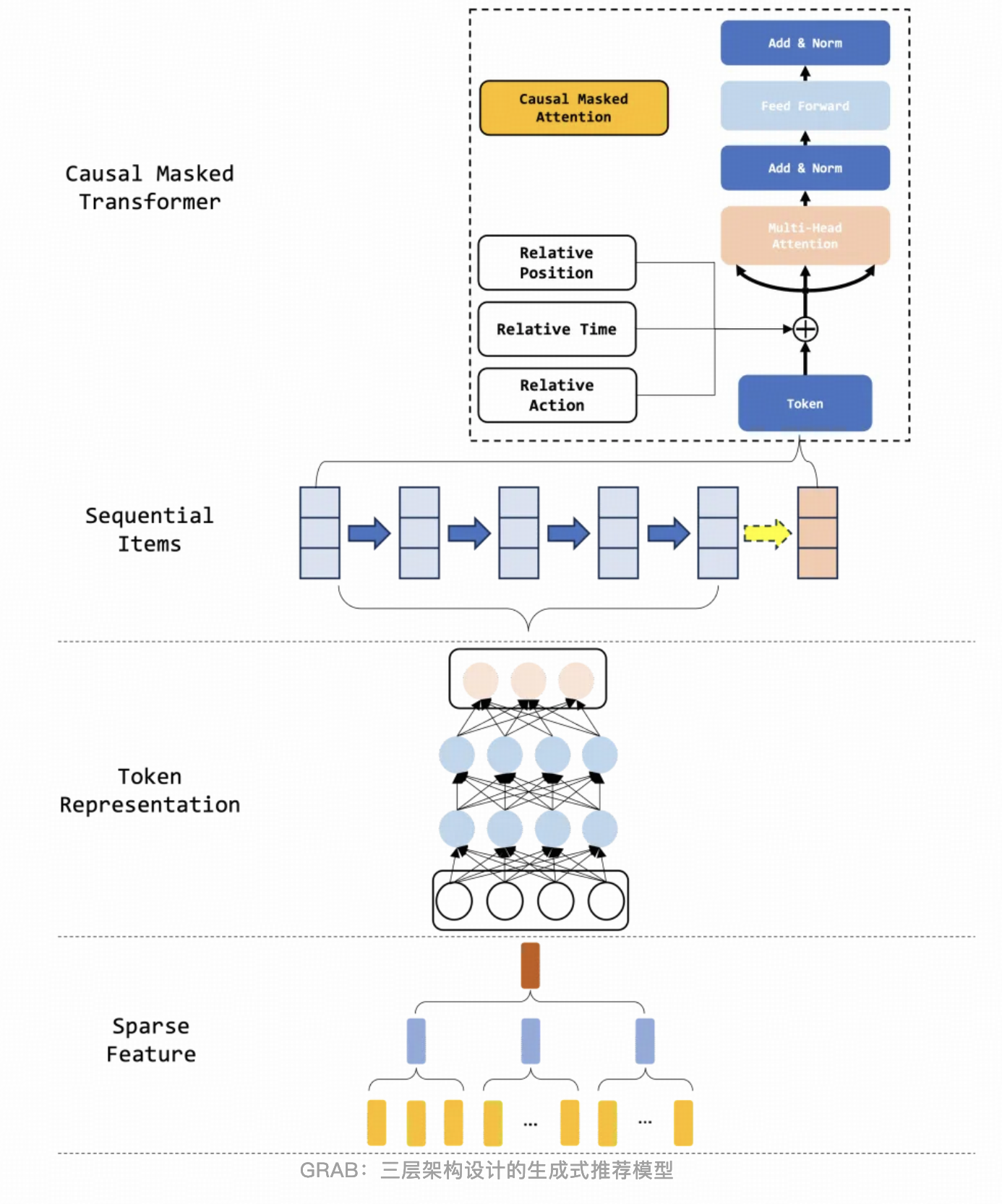
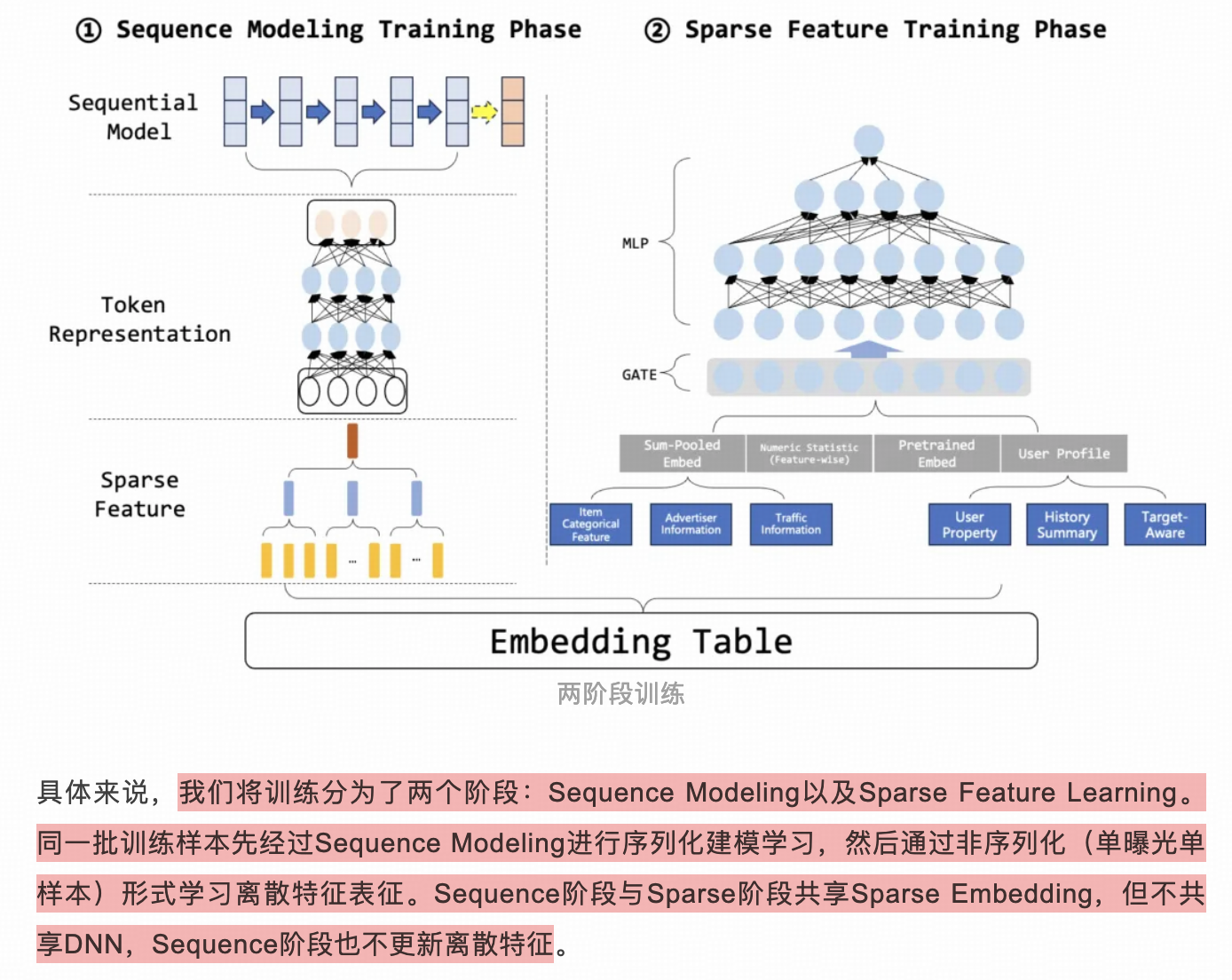
上面MTGR中提到的按用户粒度组织训练样本的问题,这篇文章给了解决方案。依然是百度祖传的两阶段训练,第一阶段固定sparse只训sequence nn,第二阶段采用单曝光样本的形式学习sparse和独立nn(这里的nn辅助sparse学习,不用于serving)。但这里引申出新问题,独立nn学习出来的sparse emb和sequence nn不匹配。
nn热启的话学习是非常快的,在流式训练的情况下,两阶段训练一直快速反复迭代,面对上一轮不一致的sparse emb,sequence nn可以快速适应,所以不匹配问题应该不严重。在天级训练情况下,这种两阶段训练估计只能缓解,达不到较好的收敛程度。
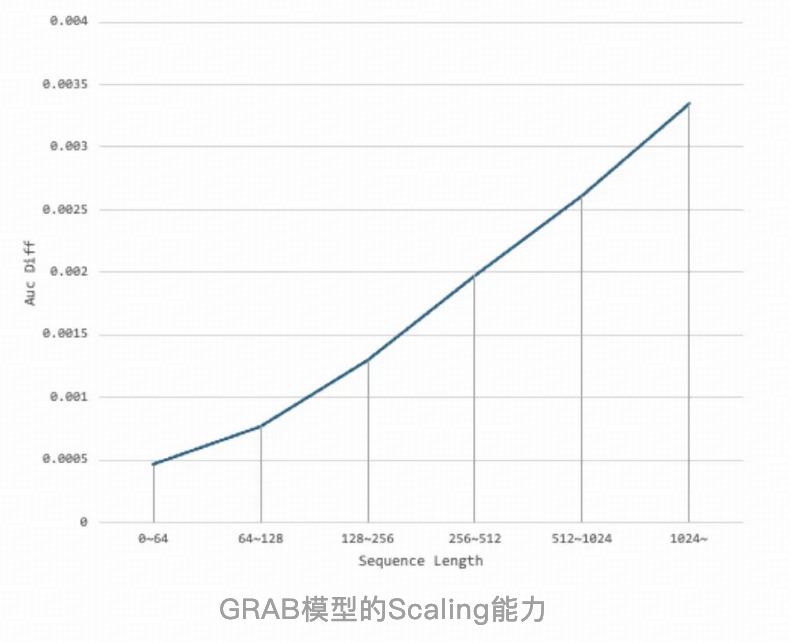
除了网络结构,这篇文章在序列样本组织、超长序列存储优化、训推性能优化等方面介绍的很详细,非常值得学习。
Scaling情况,只在序列长度上进行了验证。
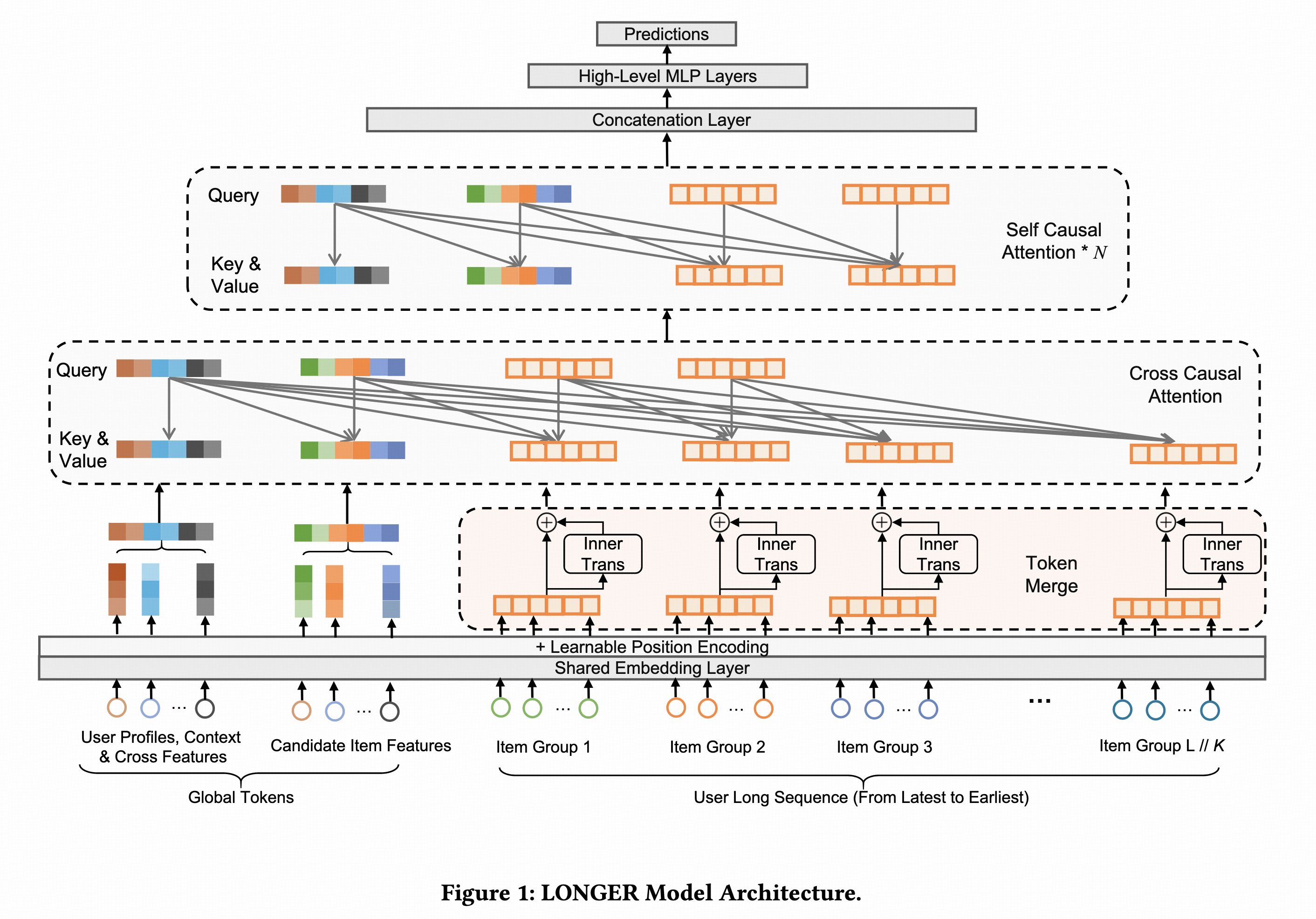
LONGER
抖音广告和电商的论文4。
序列特征中每个行为是一个token,非序列特征中每个特征是一个token。假如输入特征中,序列特征长度S,非序列特征长度N。第一层,将序列按时间顺序排列,每K个临近token通过InnerTrans聚合成一个token,序列长度从S降为S/K,第一层输出token数量是N + S/K。论文中序列长度2000,K=4可以降为500。第二层,使用最近的k个token作为query,key和value还是全部序列,其中k < S/K < S,通过causal
attention后序列长度降为k,第二层输出token数量是N + k。第三层,叠加多层的普通causal
attetion。
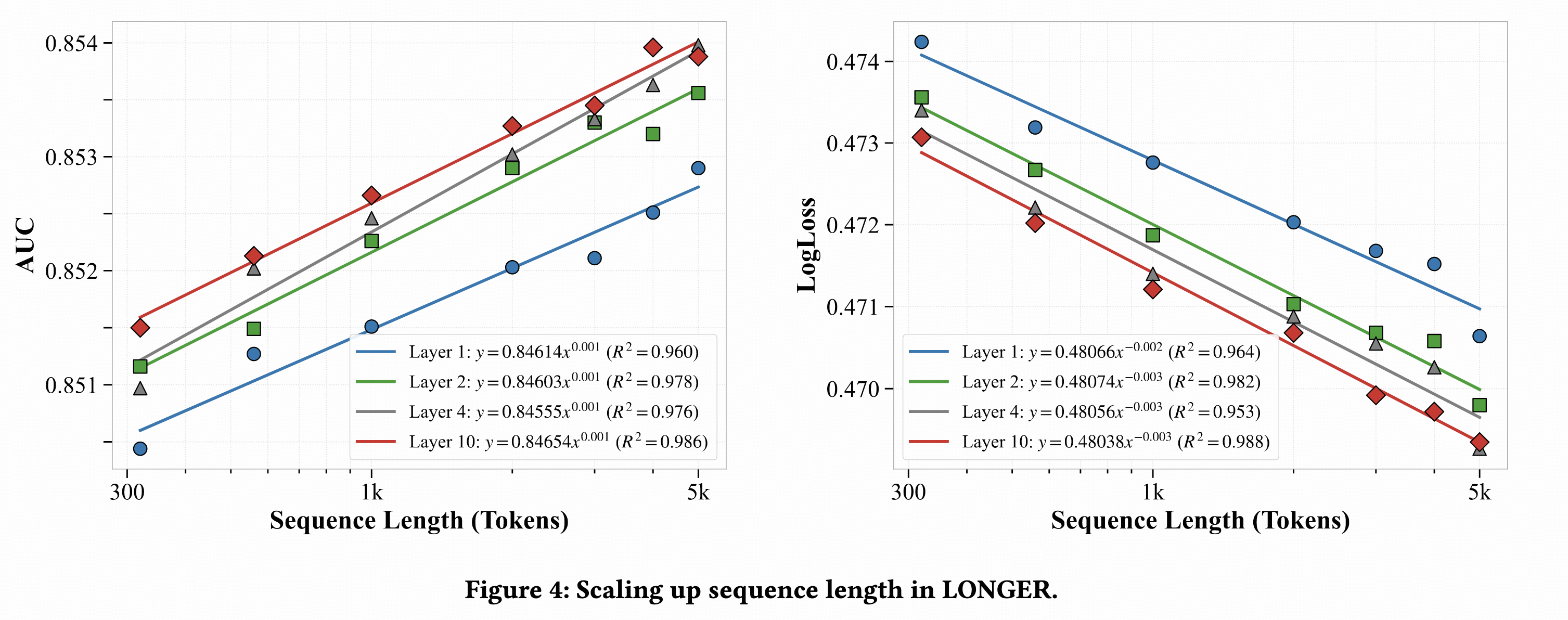
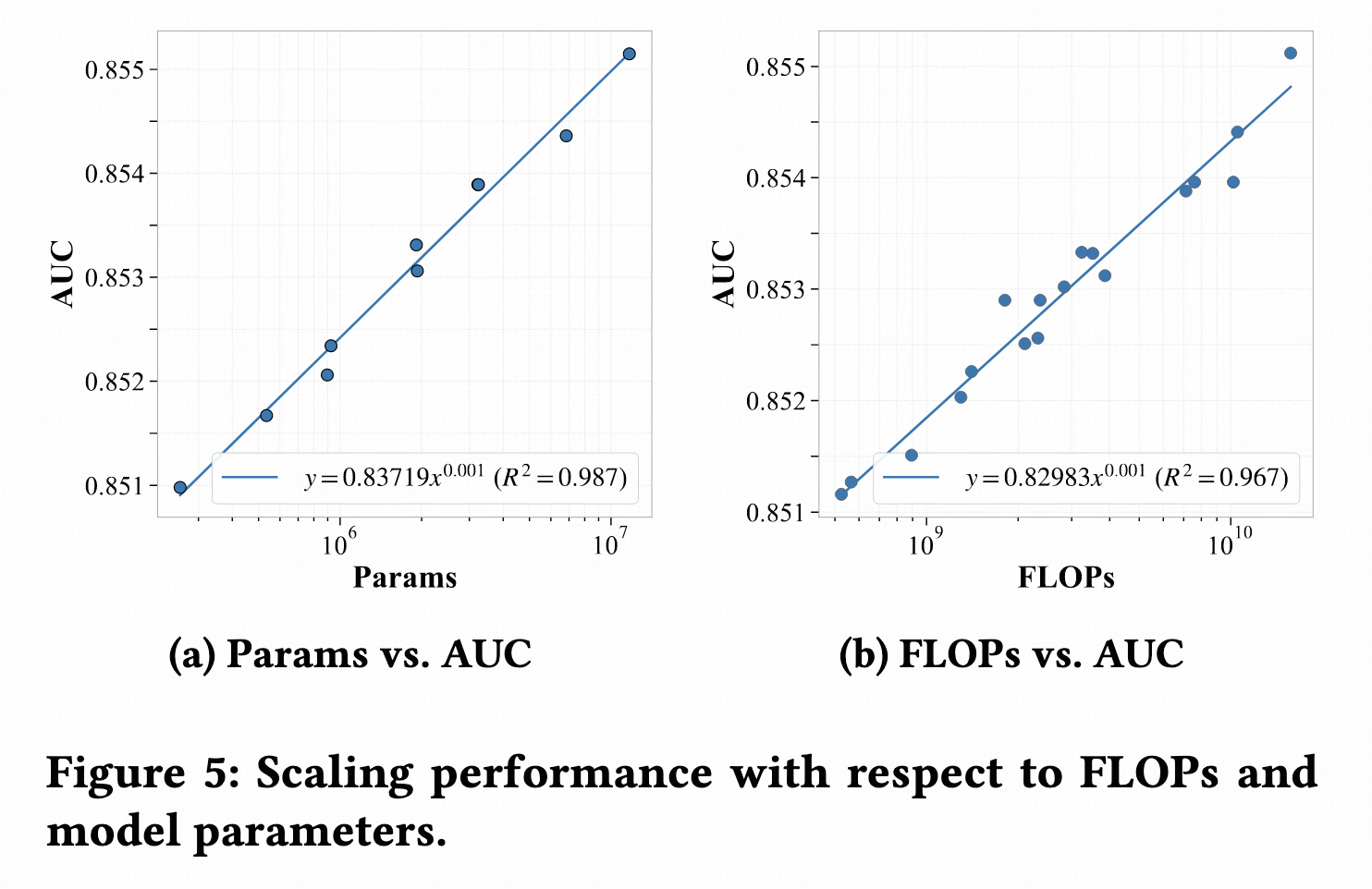
Scaling效果,在T、L、D各方向上都非常显著。
OneTrans
Tiktok推荐和电商在论文5提出的。
序列特征token化:每个行为,将item id emb和side-info emb concat后映射成一个token;
非序列特征token化:
- 方法一:将特征划分成多个group,每个group内所有特征emb concat后过一个group独立的单层mlp后得到一个token。
- 方法二:所有特征emb concat后通过mlp映射,然后split成多个token。(论文中说这个方法好,我这边实验还是方法一更好。)
输入token序列中,序列特征对应的token按时间顺序排列,不同行为类型间插入[SEP] token。采用causal attention,序列token只能看到时间更早的序列token,非序列token可以看到全部序列token以及前面的非序列token。层与层之间是pyramid的,每次attention时,只选取最近的k个token做query,因此token数量随着层数一步步减少,主要是性能提升明显,效果方面和full attention差不多。
采用了RMSNorm,并且是pre-norm。pre-norm比较符合我的认知,我自己的实验也证明确实如此。pre-norm可以保证底层emb向上层传递过程中无损,而post-norm每一层都会对输入emb进行norm因此更注重高层emb。在LLM中,最底层的词粒度emb通过层层组合,得到高层的语义emb,底层细粒度emb相对来说不太重要,因此post-norm更适合。而搜广推领域,底层emb包含的信息非常充分,向上传递过程中不能有损,因此pre-norm更适合。
![]()
Scaling方面,T、L、D各方向scale都有显著效果。
![]()
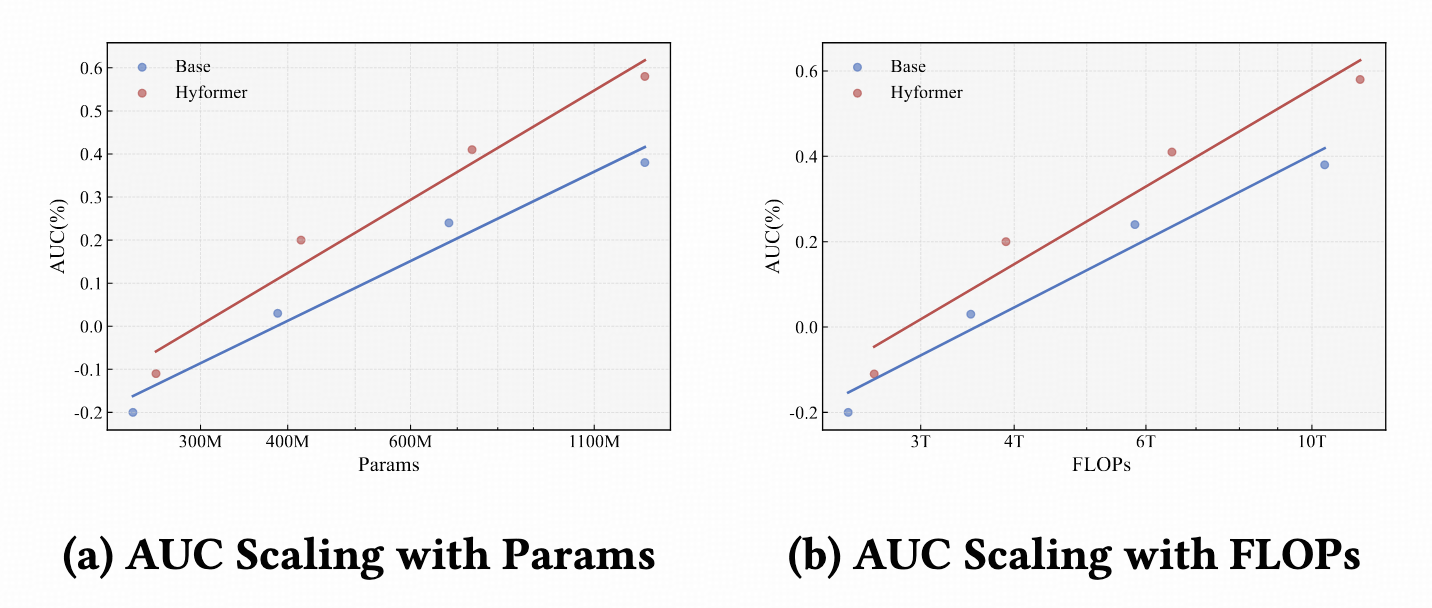
HyFormer
抖音搜索9提出的。
序列特征token化:每个行为,将item id emb和side-info emb concat后映射成一个token;
非序列特征token化:将特征划分成多个group,每个group内所有特征emb concat后过一个group独立的单层mlp后得到一个token。
Global token:第一层的是根据序列token和非序列token生成的,之后是前一层的输出。论文中生成了3个global token。
每一层包含两步:
- 第一步(Query Decoding):使用Global token做query,在序列token上做attention,将序列信息聚合到Gloabl token hidden emb上。
- 第二步(Query Boosting):Gloabl token hidden和非序列token,使用RankMixer方式进行交叉,进一步融合了非序列信息。
有多种序列的话,每个序列有独立参数,单独做此类融合。
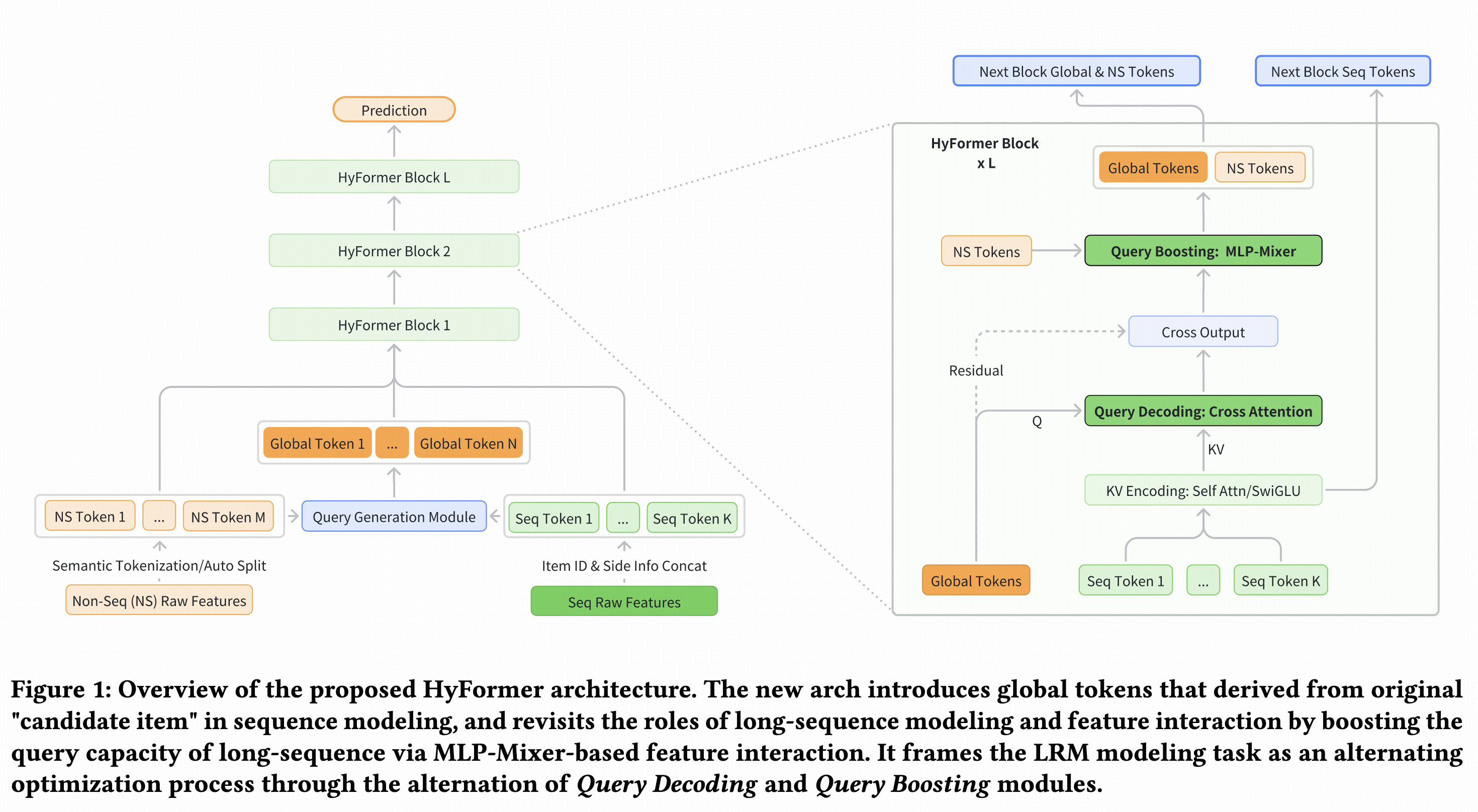
Scaling效果,比LONGER+RankMixer效果更好。
参考
- [1][Hiformer: Heterogeneous Feature Interactions Learning with
Transformers for Recommender Systems](http://arxiv.org/abs/2311.05884)
- [2][HHFT: Hierarchical Heterogeneous Feature Transformer for
Recommendation Systems](http://arxiv.org/abs/2511.20235)
- [3][RankMixer: Scaling Up Ranking Models in Industrial
Recommenders](http://arxiv.org/abs/2507.15551)
- [4][LONGER: Scaling Up Long Sequence Modeling in Industrial
Recommenders](http://arxiv.org/abs/2505.04421)
- [5][OneTrans: Unified Feature Interaction and Sequence Modeling with
One Transformer in Industrial
Recommender](http://arxiv.org/abs/2510.26104)
- [6][MTGR:美团外卖生成式推荐Scaling
Law落地实践](https://mp.weixin.qq.com/s/JiDOqD-ThU0Upp6xnNg3Nw)
- [7][GRAB-百度推荐广告生成式排序模型技术实践](https://mp.weixin.qq.com/s/mT8DmHzgc3ag57PVMqZ3Rw)
- [8][Actions Speak Louder than Words: Trillion-Parameter Sequential
Transducers for Generative
Recommendations](http://arxiv.org/abs/2402.17152)
- [9][HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction](http://arxiv.org/abs/2601.12681)