作者 formath 2025-01-12
推荐系统时长建模的常用方案
背景
介绍几种工业界比较常用的时长建模方案。
Weighted Logloss
Weighted Logloss是YouTube论文1提出的一种方法。将时长
实际中一般将loss中分母的
线上预估时,需要将预估的
时长归一化
长视频的消费时长往往更高,造成Weighted Logloss中长视频的比重更大,更倾向于优化长视频的效果。所以,为了消除视频本身长短带来的偏差,可以先将训练样本按video duration分桶,比如0-1分钟的一档,1-5分钟的一档等等,然后每档内部按消费时长分段,最后将消费时长归一化到0到1内的值,用这个归一化后的值做label进行训练。
最优解
这里如果用Weighted Logloss是否可以呢?
那么,
另外,时长归一化在后面的几种方法里都可以叠加使用。
分桶归一化的时长变换逻辑: class TimeTrans(object):
def __init__(self):
self.videoDurationTable = [0.0, 17.747, 24.707, 31.601, 35.786, 43.348, 51.91, 61.127, 89.685, 137.155]
self.timePercentileTable = [
[0.0, 3.86, 5.235, 5.64, 6.06, 6.51, 6.99, 7.47, 7.995, 8.535, 9.09, 9.675, 10.26, 10.86, 11.475, 12.09, 12.72, 13.35, 13.98, 14.595, 15.225, 15.855, 16.47, 17.025, 17.565, 18.06, 18.585, 19.11, 19.635, 20.16, 20.685, 21.195, 21.705, 22.23, 22.755, 23.295, 23.835, 24.33, 24.825, 25.305, 25.815, 26.34, 26.91, 27.72, 29.01, 30.81, 33.09, 36.255, 40.755, 47.22],
[0.0, 3.875, 5.295, 5.745, 6.225, 6.75, 7.32, 7.92, 8.58, 9.285, 10.02, 10.785, 11.595, 12.435, 13.32, 14.205, 15.12, 16.065, 16.995, 17.91, 18.855, 19.83, 20.79, 21.72, 22.62, 23.535, 24.45, 25.335, 26.145, 26.895, 27.465, 27.975, 28.47, 28.965, 29.49, 30.045, 30.63, 31.23, 31.875, 32.55, 33.225, 33.945, 34.74, 35.625, 36.645, 38.085, 40.5, 44.22, 49.86, 58.62],
[0.0, 3.95, 5.46, 6.0, 6.6, 7.275, 8.025, 8.835, 9.69, 10.62, 11.61, 12.72, 13.965, 15.24, 16.59, 18.075, 19.575, 21.09, 22.62, 24.12, 25.62, 27.195, 28.8, 30.405, 31.98, 33.405, 34.725, 35.895, 36.93, 37.785, 38.565, 39.33, 40.095, 40.875, 41.625, 42.375, 43.11, 43.905, 44.7, 45.525, 46.29, 46.935, 47.52, 48.075, 48.765, 50.01, 52.155, 55.635, 61.98, 74.775],
[0.0, 3.965, 5.445, 5.985, 6.57, 7.245, 7.98, 8.775, 9.66, 10.695, 11.79, 12.99, 14.295, 15.735, 17.295, 18.975, 20.775, 22.665, 24.615, 26.52, 28.29, 30.015, 31.905, 33.915, 35.97, 38.13, 40.29, 42.39, 44.16, 45.735, 47.07, 48.09, 48.795, 49.35, 49.86, 50.355, 50.85, 51.36, 51.885, 52.425, 52.965, 53.505, 54.105, 54.735, 55.41, 56.37, 58.11, 61.14, 66.825, 80.265],
[0.0, 3.95, 5.445, 5.985, 6.6, 7.275, 8.01, 8.865, 9.825, 10.89, 12.06, 13.395, 14.835, 16.425, 18.15, 20.04, 22.065, 24.195, 26.475, 28.89, 31.11, 33.12, 35.13, 37.32, 39.675, 42.09, 44.535, 47.04, 49.365, 51.45, 53.205, 54.66, 55.755, 56.49, 57.09, 57.675, 58.29, 58.89, 59.505, 60.15, 60.825, 61.515, 62.175, 62.88, 63.675, 64.605, 65.985, 68.865, 74.55, 88.395],
[0.0, 3.965, 5.49, 6.075, 6.72, 7.425, 8.235, 9.135, 10.14, 11.265, 12.465, 13.785, 15.285, 16.995, 18.825, 20.85, 23.07, 25.53, 28.185, 30.795, 33.555, 36.12, 38.505, 40.905, 43.62, 46.41, 49.38, 52.47, 55.575, 58.47, 61.005, 63.06, 64.59, 65.535, 66.33, 67.095, 67.845, 68.61, 69.345, 70.02, 70.725, 71.475, 72.225, 73.005, 73.89, 74.88, 75.99, 78.12, 83.19, 96.66],
[0.0, 3.98, 5.52, 6.12, 6.795, 7.56, 8.415, 9.39, 10.5, 11.715, 13.095, 14.655, 16.425, 18.345, 20.46, 22.755, 25.275, 27.975, 31.005, 34.17, 37.65, 41.055, 44.1, 47.145, 50.115, 53.385, 56.895, 60.45, 64.155, 67.86, 71.265, 74.01, 76.17, 77.535, 78.66, 79.725, 80.745, 81.795, 82.845, 83.94, 85.02, 86.145, 87.315, 88.545, 89.895, 91.32, 92.775, 94.545, 99.21, 112.845],
[0.0, 3.95, 5.46, 6.015, 6.645, 7.35, 8.145, 9.045, 10.065, 11.175, 12.45, 13.875, 15.51, 17.385, 19.485, 21.795, 24.405, 27.33, 30.45, 33.945, 37.53, 41.49, 45.615, 49.56, 53.43, 57.195, 61.095, 65.07, 69.255, 73.74, 78.63, 83.43, 87.885, 91.83, 94.725, 96.585, 98.355, 100.02, 101.685, 103.515, 105.48, 107.91, 110.61, 113.265, 115.905, 118.59, 121.545, 125.22, 129.105, 139.95],
[0.0, 3.92, 5.4, 5.955, 6.57, 7.275, 8.07, 8.97, 9.96, 11.13, 12.435, 13.92, 15.615, 17.565, 19.815, 22.35, 25.23, 28.575, 32.34, 36.315, 40.77, 45.63, 50.895, 56.34, 62.025, 67.95, 73.62, 79.335, 85.095, 91.065, 97.29, 103.65, 110.205, 117.285, 124.335, 130.23, 133.86, 137.055, 140.85, 144.735, 148.935, 153.765, 159.375, 164.955, 171.345, 178.68, 185.925, 193.545, 203.265, 214.425],
[0.0, 3.95, 5.46, 6.045, 6.705, 7.455, 8.31, 9.285, 10.44, 11.775, 13.275, 15.03, 17.025, 19.365, 22.095, 25.275, 28.95, 33.12, 37.89, 43.08, 48.885, 55.05, 62.085, 69.525, 77.46, 86.085, 95.13, 104.385, 114.45, 124.65, 135.3, 146.94, 159.825, 172.92, 186.735, 201.57, 216.36, 225.39, 236.025, 247.59, 259.875, 273.195, 288.12, 304.395, 323.325, 344.235, 365.625, 399.33, 439.785, 508.44]
]
self.maxReadTime = 3 # 阅读时长不能超过视频时长的3倍
def getIdx(self, percentileList, score):
if score >= percentileList[-1]:
return len(percentileList) - 1
left = 0
right = len(percentileList)
while left <= right:
mid = (left + right) // 2
if percentileList[mid] < score:
left = mid + 1
elif percentileList[mid] > score:
right = mid - 1
else:
return mid
return right
# 时长归一化
def encode(self, videoTime, readTime):
if videoTime <= 0 or readTime <= 0:
videoTime = 1e-8
readTime = 1e-8
elif readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
bukIdx = self.getIdx(timePercentileList, readTime)
if bukIdx < 0:
return 0.0
elif bukIdx == len(timePercentileList) - 1:
lowerLabel = 1.0 / len(timePercentileList) * bukIdx
upperLabel = 1.0
label = lowerLabel + (readTime - timePercentileList[bukIdx]) * (upperLabel - lowerLabel) / (self.maxReadTime * videoTime - timePercentileList[bukIdx])
else:
lowerLabel = 1.0 / len(timePercentileList) * bukIdx
upperLabel = 1.0 / len(timePercentileList) * (bukIdx + 1)
label = lowerLabel + (readTime - timePercentileList[bukIdx]) * (upperLabel - lowerLabel) / (timePercentileList[bukIdx+1] - timePercentileList[bukIdx])
return label
# 预估时长还原
def decode(self, videoTime, pScore):
if videoTime <= 0 or pScore <= 0:
return 0.0
elif pScore >= 1:
return self.maxReadTime * videoTime
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
bukIdx = int(pScore * len(timePercentileList))
if bukIdx == len(timePercentileList) - 1:
lowerLabel = 1.0 / len(timePercentileList) * bukIdx
upperLabel = 1.0
if self.maxReadTime * videoTime > timePercentileList[bukIdx]:
readTime = timePercentileList[bukIdx] + (pScore - lowerLabel) * (self.maxReadTime * videoTime - timePercentileList[bukIdx]) / (upperLabel - lowerLabel)
else:
readTime = self.maxReadTime * videoTime
else:
lowerLabel = 1.0 / len(timePercentileList) * bukIdx
upperLabel = 1.0 / len(timePercentileList) * (bukIdx + 1)
readTime = timePercentileList[bukIdx] + (pScore - lowerLabel) * (timePercentileList[bukIdx+1] - timePercentileList[bukIdx]) / (upperLabel - lowerLabel)
if readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
return readTime
# 测试
timeTrans = TimeTrans()
videoTime = 16
readTime = 8
timeLabel = timeTrans.encode(videoTime, readTime)
print(timeLabel)
readTimeRevocery = timeTrans.decode(videoTime, timeLabel)
print(readTimeRevocery)
CREAD
CREAD是快手的论文2中提出的方法。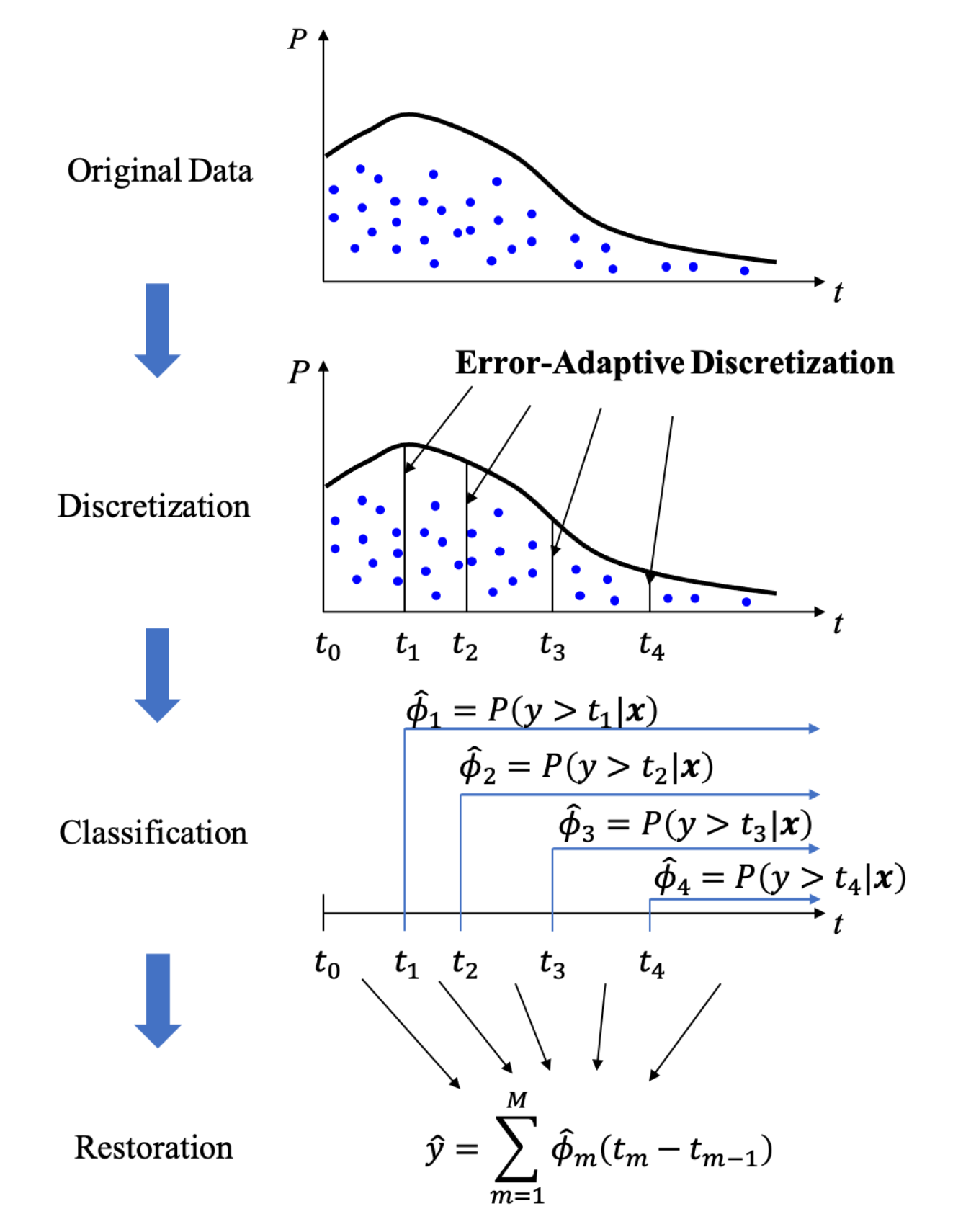
将消费时长从小到大排序,比如是
实际上,训练时除了m个分类任务,还增加了两个其他损失,一个是还原时长与真实时长的偏差(采用Huber
loss),另一个是
CREAD的时长变换逻辑: class TimeTrans(object):
def __init__(self):
self.videoDurationTable = [0.0, 17.747, 24.707, 31.601, 35.786, 43.348, 51.91, 61.127, 89.685, 137.155]
self.timePercentileTable = [
[0.0, 3.86, 5.235, 5.64, 6.06, 6.51, 6.99, 7.47, 7.995, 8.535, 9.09, 9.675, 10.26, 10.86, 11.475, 12.09, 12.72, 13.35, 13.98, 14.595, 15.225, 15.855, 16.47, 17.025, 17.565, 18.06, 18.585, 19.11, 19.635, 20.16, 20.685, 21.195, 21.705, 22.23, 22.755, 23.295, 23.835, 24.33, 24.825, 25.305, 25.815, 26.34, 26.91, 27.72, 29.01, 30.81, 33.09, 36.255, 40.755, 47.22],
[0.0, 3.875, 5.295, 5.745, 6.225, 6.75, 7.32, 7.92, 8.58, 9.285, 10.02, 10.785, 11.595, 12.435, 13.32, 14.205, 15.12, 16.065, 16.995, 17.91, 18.855, 19.83, 20.79, 21.72, 22.62, 23.535, 24.45, 25.335, 26.145, 26.895, 27.465, 27.975, 28.47, 28.965, 29.49, 30.045, 30.63, 31.23, 31.875, 32.55, 33.225, 33.945, 34.74, 35.625, 36.645, 38.085, 40.5, 44.22, 49.86, 58.62],
[0.0, 3.95, 5.46, 6.0, 6.6, 7.275, 8.025, 8.835, 9.69, 10.62, 11.61, 12.72, 13.965, 15.24, 16.59, 18.075, 19.575, 21.09, 22.62, 24.12, 25.62, 27.195, 28.8, 30.405, 31.98, 33.405, 34.725, 35.895, 36.93, 37.785, 38.565, 39.33, 40.095, 40.875, 41.625, 42.375, 43.11, 43.905, 44.7, 45.525, 46.29, 46.935, 47.52, 48.075, 48.765, 50.01, 52.155, 55.635, 61.98, 74.775],
[0.0, 3.965, 5.445, 5.985, 6.57, 7.245, 7.98, 8.775, 9.66, 10.695, 11.79, 12.99, 14.295, 15.735, 17.295, 18.975, 20.775, 22.665, 24.615, 26.52, 28.29, 30.015, 31.905, 33.915, 35.97, 38.13, 40.29, 42.39, 44.16, 45.735, 47.07, 48.09, 48.795, 49.35, 49.86, 50.355, 50.85, 51.36, 51.885, 52.425, 52.965, 53.505, 54.105, 54.735, 55.41, 56.37, 58.11, 61.14, 66.825, 80.265],
[0.0, 3.95, 5.445, 5.985, 6.6, 7.275, 8.01, 8.865, 9.825, 10.89, 12.06, 13.395, 14.835, 16.425, 18.15, 20.04, 22.065, 24.195, 26.475, 28.89, 31.11, 33.12, 35.13, 37.32, 39.675, 42.09, 44.535, 47.04, 49.365, 51.45, 53.205, 54.66, 55.755, 56.49, 57.09, 57.675, 58.29, 58.89, 59.505, 60.15, 60.825, 61.515, 62.175, 62.88, 63.675, 64.605, 65.985, 68.865, 74.55, 88.395],
[0.0, 3.965, 5.49, 6.075, 6.72, 7.425, 8.235, 9.135, 10.14, 11.265, 12.465, 13.785, 15.285, 16.995, 18.825, 20.85, 23.07, 25.53, 28.185, 30.795, 33.555, 36.12, 38.505, 40.905, 43.62, 46.41, 49.38, 52.47, 55.575, 58.47, 61.005, 63.06, 64.59, 65.535, 66.33, 67.095, 67.845, 68.61, 69.345, 70.02, 70.725, 71.475, 72.225, 73.005, 73.89, 74.88, 75.99, 78.12, 83.19, 96.66],
[0.0, 3.98, 5.52, 6.12, 6.795, 7.56, 8.415, 9.39, 10.5, 11.715, 13.095, 14.655, 16.425, 18.345, 20.46, 22.755, 25.275, 27.975, 31.005, 34.17, 37.65, 41.055, 44.1, 47.145, 50.115, 53.385, 56.895, 60.45, 64.155, 67.86, 71.265, 74.01, 76.17, 77.535, 78.66, 79.725, 80.745, 81.795, 82.845, 83.94, 85.02, 86.145, 87.315, 88.545, 89.895, 91.32, 92.775, 94.545, 99.21, 112.845],
[0.0, 3.95, 5.46, 6.015, 6.645, 7.35, 8.145, 9.045, 10.065, 11.175, 12.45, 13.875, 15.51, 17.385, 19.485, 21.795, 24.405, 27.33, 30.45, 33.945, 37.53, 41.49, 45.615, 49.56, 53.43, 57.195, 61.095, 65.07, 69.255, 73.74, 78.63, 83.43, 87.885, 91.83, 94.725, 96.585, 98.355, 100.02, 101.685, 103.515, 105.48, 107.91, 110.61, 113.265, 115.905, 118.59, 121.545, 125.22, 129.105, 139.95],
[0.0, 3.92, 5.4, 5.955, 6.57, 7.275, 8.07, 8.97, 9.96, 11.13, 12.435, 13.92, 15.615, 17.565, 19.815, 22.35, 25.23, 28.575, 32.34, 36.315, 40.77, 45.63, 50.895, 56.34, 62.025, 67.95, 73.62, 79.335, 85.095, 91.065, 97.29, 103.65, 110.205, 117.285, 124.335, 130.23, 133.86, 137.055, 140.85, 144.735, 148.935, 153.765, 159.375, 164.955, 171.345, 178.68, 185.925, 193.545, 203.265, 214.425],
[0.0, 3.95, 5.46, 6.045, 6.705, 7.455, 8.31, 9.285, 10.44, 11.775, 13.275, 15.03, 17.025, 19.365, 22.095, 25.275, 28.95, 33.12, 37.89, 43.08, 48.885, 55.05, 62.085, 69.525, 77.46, 86.085, 95.13, 104.385, 114.45, 124.65, 135.3, 146.94, 159.825, 172.92, 186.735, 201.57, 216.36, 225.39, 236.025, 247.59, 259.875, 273.195, 288.12, 304.395, 323.325, 344.235, 365.625, 399.33, 439.785, 508.44]
]
self.maxReadTime = 3
def getIdx(self, percentileList, score):
if score >= percentileList[-1]:
return len(percentileList) - 1
left = 0
right = len(percentileList)
while left <= right:
mid = (left + right) // 2
if percentileList[mid] < score:
left = mid + 1
elif percentileList[mid] > score:
right = mid - 1
else:
return mid
return right
# 时长归一化
def encode(self, videoTime, readTime):
if videoTime <= 0 or readTime <= 0:
videoTime = 1e-8
readTime = 1e-8
elif readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
label = [1.0 if readTime > thr else 0.0 for thr in timePercentileList]
return label
# 预估时长还原
def decode(self, videoTime, pScore):
if videoTime <= 0:
return 0.0
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
readTime = timePercentileList[0]
for i in range(1, len(timePercentileList)):
readTime += (timePercentileList[i] - timePercentileList[i-1]) * pScore[i]
return readTime
# 测试
timeTrans = TimeTrans()
videoTime = 16
readTime = 8
timeLabel = timeTrans.encode(videoTime, readTime)
print(timeLabel)
readTimeRevocery = timeTrans.decode(videoTime, timeLabel)
print(readTimeRevocery)
EMD
传统的多分类任务,label中只有一个是正类,其他是负类,类别之间没有关系。但是在某些任务中,类别之间是有一定关系的。下图是收入预估的一个例子,adult是真实label,AB两种分布的loss是一样的,但明显B比A更合理一点。在时长预估上也有同样的道理,比如把时长分成10个区间,真实label在区间5,做多分类任务,我们希望5区间的预估概率最高,向左向右的概率平滑的降低。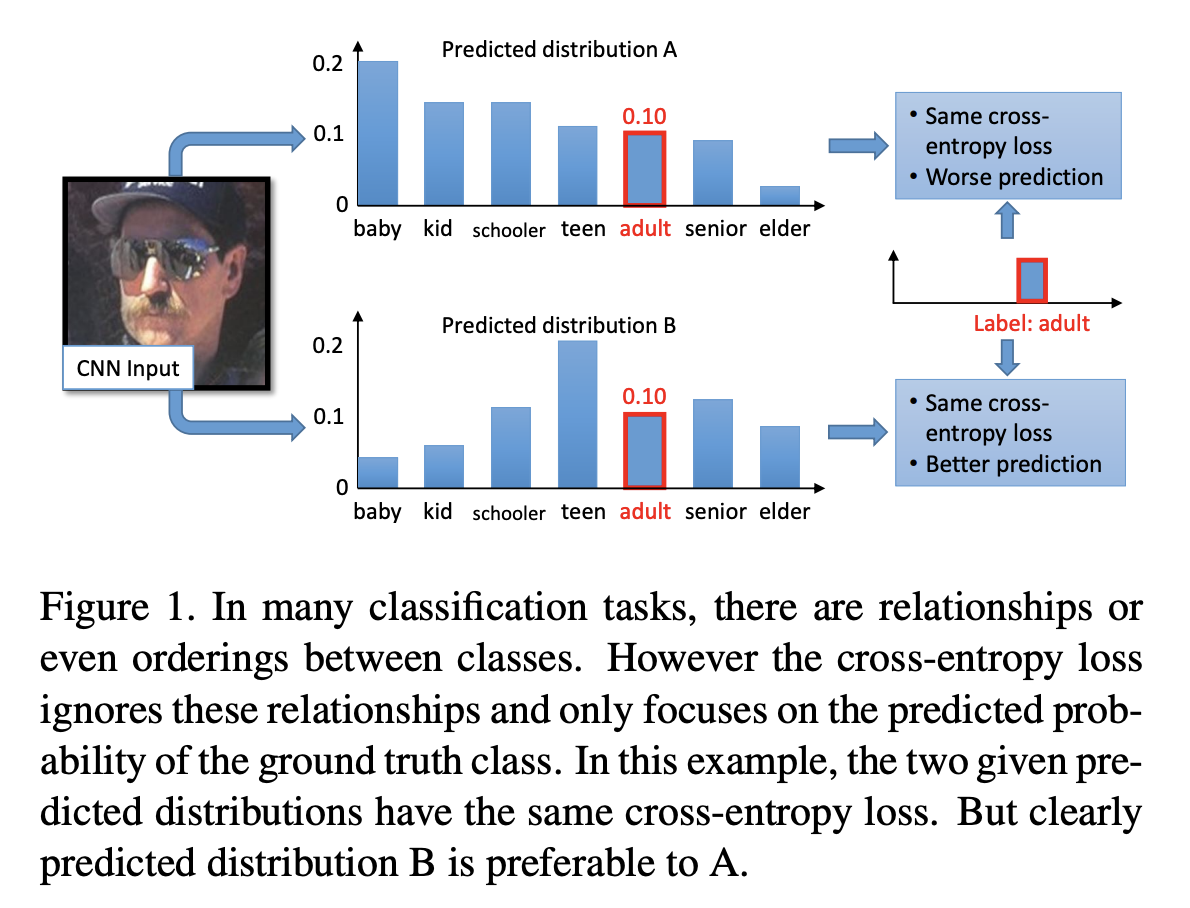
Earth Mover’s Distance(EMD)论文3使用的是Squared EMD Loss:
论文3不是做时长预估的,我们这里为时长预估任务把损失改成分类的EMD
Loss。 和CREAD类似,将消费时长从小到大排序,比如是
线上预估时,可以通过以下公式还原成时长,和CREAD很像。
还原时也可以更简化:
EMD和CREAD从不同的出发角度,得到了近似的工程实现。
EMD的时长变换逻辑: class TimeTrans(object):
def __init__(self):
self.videoDurationTable = [0.0, 17.747, 24.707, 31.601, 35.786, 43.348, 51.91, 61.127, 89.685, 137.155]
self.timePercentileTable = [
[0.0, 3.86, 5.235, 5.64, 6.06, 6.51, 6.99, 7.47, 7.995, 8.535, 9.09, 9.675, 10.26, 10.86, 11.475, 12.09, 12.72, 13.35, 13.98, 14.595, 15.225, 15.855, 16.47, 17.025, 17.565, 18.06, 18.585, 19.11, 19.635, 20.16, 20.685, 21.195, 21.705, 22.23, 22.755, 23.295, 23.835, 24.33, 24.825, 25.305, 25.815, 26.34, 26.91, 27.72, 29.01, 30.81, 33.09, 36.255, 40.755, 47.22],
[0.0, 3.875, 5.295, 5.745, 6.225, 6.75, 7.32, 7.92, 8.58, 9.285, 10.02, 10.785, 11.595, 12.435, 13.32, 14.205, 15.12, 16.065, 16.995, 17.91, 18.855, 19.83, 20.79, 21.72, 22.62, 23.535, 24.45, 25.335, 26.145, 26.895, 27.465, 27.975, 28.47, 28.965, 29.49, 30.045, 30.63, 31.23, 31.875, 32.55, 33.225, 33.945, 34.74, 35.625, 36.645, 38.085, 40.5, 44.22, 49.86, 58.62],
[0.0, 3.95, 5.46, 6.0, 6.6, 7.275, 8.025, 8.835, 9.69, 10.62, 11.61, 12.72, 13.965, 15.24, 16.59, 18.075, 19.575, 21.09, 22.62, 24.12, 25.62, 27.195, 28.8, 30.405, 31.98, 33.405, 34.725, 35.895, 36.93, 37.785, 38.565, 39.33, 40.095, 40.875, 41.625, 42.375, 43.11, 43.905, 44.7, 45.525, 46.29, 46.935, 47.52, 48.075, 48.765, 50.01, 52.155, 55.635, 61.98, 74.775],
[0.0, 3.965, 5.445, 5.985, 6.57, 7.245, 7.98, 8.775, 9.66, 10.695, 11.79, 12.99, 14.295, 15.735, 17.295, 18.975, 20.775, 22.665, 24.615, 26.52, 28.29, 30.015, 31.905, 33.915, 35.97, 38.13, 40.29, 42.39, 44.16, 45.735, 47.07, 48.09, 48.795, 49.35, 49.86, 50.355, 50.85, 51.36, 51.885, 52.425, 52.965, 53.505, 54.105, 54.735, 55.41, 56.37, 58.11, 61.14, 66.825, 80.265],
[0.0, 3.95, 5.445, 5.985, 6.6, 7.275, 8.01, 8.865, 9.825, 10.89, 12.06, 13.395, 14.835, 16.425, 18.15, 20.04, 22.065, 24.195, 26.475, 28.89, 31.11, 33.12, 35.13, 37.32, 39.675, 42.09, 44.535, 47.04, 49.365, 51.45, 53.205, 54.66, 55.755, 56.49, 57.09, 57.675, 58.29, 58.89, 59.505, 60.15, 60.825, 61.515, 62.175, 62.88, 63.675, 64.605, 65.985, 68.865, 74.55, 88.395],
[0.0, 3.965, 5.49, 6.075, 6.72, 7.425, 8.235, 9.135, 10.14, 11.265, 12.465, 13.785, 15.285, 16.995, 18.825, 20.85, 23.07, 25.53, 28.185, 30.795, 33.555, 36.12, 38.505, 40.905, 43.62, 46.41, 49.38, 52.47, 55.575, 58.47, 61.005, 63.06, 64.59, 65.535, 66.33, 67.095, 67.845, 68.61, 69.345, 70.02, 70.725, 71.475, 72.225, 73.005, 73.89, 74.88, 75.99, 78.12, 83.19, 96.66],
[0.0, 3.98, 5.52, 6.12, 6.795, 7.56, 8.415, 9.39, 10.5, 11.715, 13.095, 14.655, 16.425, 18.345, 20.46, 22.755, 25.275, 27.975, 31.005, 34.17, 37.65, 41.055, 44.1, 47.145, 50.115, 53.385, 56.895, 60.45, 64.155, 67.86, 71.265, 74.01, 76.17, 77.535, 78.66, 79.725, 80.745, 81.795, 82.845, 83.94, 85.02, 86.145, 87.315, 88.545, 89.895, 91.32, 92.775, 94.545, 99.21, 112.845],
[0.0, 3.95, 5.46, 6.015, 6.645, 7.35, 8.145, 9.045, 10.065, 11.175, 12.45, 13.875, 15.51, 17.385, 19.485, 21.795, 24.405, 27.33, 30.45, 33.945, 37.53, 41.49, 45.615, 49.56, 53.43, 57.195, 61.095, 65.07, 69.255, 73.74, 78.63, 83.43, 87.885, 91.83, 94.725, 96.585, 98.355, 100.02, 101.685, 103.515, 105.48, 107.91, 110.61, 113.265, 115.905, 118.59, 121.545, 125.22, 129.105, 139.95],
[0.0, 3.92, 5.4, 5.955, 6.57, 7.275, 8.07, 8.97, 9.96, 11.13, 12.435, 13.92, 15.615, 17.565, 19.815, 22.35, 25.23, 28.575, 32.34, 36.315, 40.77, 45.63, 50.895, 56.34, 62.025, 67.95, 73.62, 79.335, 85.095, 91.065, 97.29, 103.65, 110.205, 117.285, 124.335, 130.23, 133.86, 137.055, 140.85, 144.735, 148.935, 153.765, 159.375, 164.955, 171.345, 178.68, 185.925, 193.545, 203.265, 214.425],
[0.0, 3.95, 5.46, 6.045, 6.705, 7.455, 8.31, 9.285, 10.44, 11.775, 13.275, 15.03, 17.025, 19.365, 22.095, 25.275, 28.95, 33.12, 37.89, 43.08, 48.885, 55.05, 62.085, 69.525, 77.46, 86.085, 95.13, 104.385, 114.45, 124.65, 135.3, 146.94, 159.825, 172.92, 186.735, 201.57, 216.36, 225.39, 236.025, 247.59, 259.875, 273.195, 288.12, 304.395, 323.325, 344.235, 365.625, 399.33, 439.785, 508.44]
]
self.maxReadTime = 3 # 阅读时长不能超过视频时长的3倍
def getIdx(self, percentileList, score):
if score >= percentileList[-1]:
return len(percentileList) - 1
left = 0
right = len(percentileList)
while left <= right:
mid = (left + right) // 2
if percentileList[mid] < score:
left = mid + 1
elif percentileList[mid] > score:
right = mid - 1
else:
return mid
return right
def cdf(self, scores):
result = []
cur_sum = 0.0
for score in scores:
cur_sum += score
result.append(cur_sum)
return result
# 时长归一化
def encode(self, videoTime, readTime):
if videoTime <= 0 or readTime <= 0:
videoTime = 1e-8
readTime = 1e-8
elif readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
bukIdx = self.getIdx(timePercentileList, readTime)
label = [1.0 if i == bukIdx else 0.0 for i in range(len(timePercentileList))]
return label
# 预估时长还原
def decode(self, videoTime, pScore):
if videoTime <= 0:
return 0.0
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
cdfResult = self.cdf(pScore)
readTime = timePercentileList[0]
for i in range(1, len(timePercentileList)):
readTime += (timePercentileList[i] - timePercentileList[i-1]) * (1 - cdfResult[i-1])
if readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
return readTime
# 测试
timeTrans = TimeTrans()
videoTime = 16
readTime = 8
timeLabel = timeTrans.encode(videoTime, readTime)
print(timeLabel)
readTimeRevocery = timeTrans.decode(videoTime, timeLabel)
print(readTimeRevocery)
Distill Softmax
和EMD有点类似,Distill Softmax也考虑类别之间的关系,只不过EMD从预估值分布角度考虑,而Distill Softmax是从label角度考虑,直接将时长做成了平滑的多分类soft-label。比如,把时长分成10个区间,真实label在区间5,本来的多分类label是[0,0,0,0,1,0,0,0,0,0],这里对时长做了平滑,希望5区间的预估概率最高,向左向右的概率平滑的降低,得到[0.001,0.005,0.03,0.1,0.7,0.1,0.05,0.008,0.005,0.001]。
具体做法,时长先做laplace分布或高斯变换,得到每个区间的概率值,越靠近真实label的区间概率越大,然后归一化即可。
def laplacePdf(self, x, mean, variance=1.0):
return 1.0 / (2.0 * variance) * np.exp(-1.0 * np.abs(np.array(x) - np.array(mean)) / variance) + 1e-7
def distill(self, timeLabel, labelPercentileList):
probs = self.laplacePdf(timeLabel, labelPercentileList)
probsSum = np.sum(probs)
softLabel = probs / probsSum
return softLabel
损失函数就是多分类交叉熵:
线上预估时,可以通过以下公式还原成时长,和EMD一样。
Distill Softmax能和EMD一起用,既先做soft-label变换后,再使用EMD
Loss。
Distill Softmax的时长变换逻辑: class TimeTrans(object):
def __init__(self):
self.videoDurationTable = [0.0, 17.747, 24.707, 31.601, 35.786, 43.348, 51.91, 61.127, 89.685, 137.155]
self.timePercentileTable = [
[0.0, 3.86, 5.235, 5.64, 6.06, 6.51, 6.99, 7.47, 7.995, 8.535, 9.09, 9.675, 10.26, 10.86, 11.475, 12.09, 12.72, 13.35, 13.98, 14.595, 15.225, 15.855, 16.47, 17.025, 17.565, 18.06, 18.585, 19.11, 19.635, 20.16, 20.685, 21.195, 21.705, 22.23, 22.755, 23.295, 23.835, 24.33, 24.825, 25.305, 25.815, 26.34, 26.91, 27.72, 29.01, 30.81, 33.09, 36.255, 40.755, 47.22],
[0.0, 3.875, 5.295, 5.745, 6.225, 6.75, 7.32, 7.92, 8.58, 9.285, 10.02, 10.785, 11.595, 12.435, 13.32, 14.205, 15.12, 16.065, 16.995, 17.91, 18.855, 19.83, 20.79, 21.72, 22.62, 23.535, 24.45, 25.335, 26.145, 26.895, 27.465, 27.975, 28.47, 28.965, 29.49, 30.045, 30.63, 31.23, 31.875, 32.55, 33.225, 33.945, 34.74, 35.625, 36.645, 38.085, 40.5, 44.22, 49.86, 58.62],
[0.0, 3.95, 5.46, 6.0, 6.6, 7.275, 8.025, 8.835, 9.69, 10.62, 11.61, 12.72, 13.965, 15.24, 16.59, 18.075, 19.575, 21.09, 22.62, 24.12, 25.62, 27.195, 28.8, 30.405, 31.98, 33.405, 34.725, 35.895, 36.93, 37.785, 38.565, 39.33, 40.095, 40.875, 41.625, 42.375, 43.11, 43.905, 44.7, 45.525, 46.29, 46.935, 47.52, 48.075, 48.765, 50.01, 52.155, 55.635, 61.98, 74.775],
[0.0, 3.965, 5.445, 5.985, 6.57, 7.245, 7.98, 8.775, 9.66, 10.695, 11.79, 12.99, 14.295, 15.735, 17.295, 18.975, 20.775, 22.665, 24.615, 26.52, 28.29, 30.015, 31.905, 33.915, 35.97, 38.13, 40.29, 42.39, 44.16, 45.735, 47.07, 48.09, 48.795, 49.35, 49.86, 50.355, 50.85, 51.36, 51.885, 52.425, 52.965, 53.505, 54.105, 54.735, 55.41, 56.37, 58.11, 61.14, 66.825, 80.265],
[0.0, 3.95, 5.445, 5.985, 6.6, 7.275, 8.01, 8.865, 9.825, 10.89, 12.06, 13.395, 14.835, 16.425, 18.15, 20.04, 22.065, 24.195, 26.475, 28.89, 31.11, 33.12, 35.13, 37.32, 39.675, 42.09, 44.535, 47.04, 49.365, 51.45, 53.205, 54.66, 55.755, 56.49, 57.09, 57.675, 58.29, 58.89, 59.505, 60.15, 60.825, 61.515, 62.175, 62.88, 63.675, 64.605, 65.985, 68.865, 74.55, 88.395],
[0.0, 3.965, 5.49, 6.075, 6.72, 7.425, 8.235, 9.135, 10.14, 11.265, 12.465, 13.785, 15.285, 16.995, 18.825, 20.85, 23.07, 25.53, 28.185, 30.795, 33.555, 36.12, 38.505, 40.905, 43.62, 46.41, 49.38, 52.47, 55.575, 58.47, 61.005, 63.06, 64.59, 65.535, 66.33, 67.095, 67.845, 68.61, 69.345, 70.02, 70.725, 71.475, 72.225, 73.005, 73.89, 74.88, 75.99, 78.12, 83.19, 96.66],
[0.0, 3.98, 5.52, 6.12, 6.795, 7.56, 8.415, 9.39, 10.5, 11.715, 13.095, 14.655, 16.425, 18.345, 20.46, 22.755, 25.275, 27.975, 31.005, 34.17, 37.65, 41.055, 44.1, 47.145, 50.115, 53.385, 56.895, 60.45, 64.155, 67.86, 71.265, 74.01, 76.17, 77.535, 78.66, 79.725, 80.745, 81.795, 82.845, 83.94, 85.02, 86.145, 87.315, 88.545, 89.895, 91.32, 92.775, 94.545, 99.21, 112.845],
[0.0, 3.95, 5.46, 6.015, 6.645, 7.35, 8.145, 9.045, 10.065, 11.175, 12.45, 13.875, 15.51, 17.385, 19.485, 21.795, 24.405, 27.33, 30.45, 33.945, 37.53, 41.49, 45.615, 49.56, 53.43, 57.195, 61.095, 65.07, 69.255, 73.74, 78.63, 83.43, 87.885, 91.83, 94.725, 96.585, 98.355, 100.02, 101.685, 103.515, 105.48, 107.91, 110.61, 113.265, 115.905, 118.59, 121.545, 125.22, 129.105, 139.95],
[0.0, 3.92, 5.4, 5.955, 6.57, 7.275, 8.07, 8.97, 9.96, 11.13, 12.435, 13.92, 15.615, 17.565, 19.815, 22.35, 25.23, 28.575, 32.34, 36.315, 40.77, 45.63, 50.895, 56.34, 62.025, 67.95, 73.62, 79.335, 85.095, 91.065, 97.29, 103.65, 110.205, 117.285, 124.335, 130.23, 133.86, 137.055, 140.85, 144.735, 148.935, 153.765, 159.375, 164.955, 171.345, 178.68, 185.925, 193.545, 203.265, 214.425],
[0.0, 3.95, 5.46, 6.045, 6.705, 7.455, 8.31, 9.285, 10.44, 11.775, 13.275, 15.03, 17.025, 19.365, 22.095, 25.275, 28.95, 33.12, 37.89, 43.08, 48.885, 55.05, 62.085, 69.525, 77.46, 86.085, 95.13, 104.385, 114.45, 124.65, 135.3, 146.94, 159.825, 172.92, 186.735, 201.57, 216.36, 225.39, 236.025, 247.59, 259.875, 273.195, 288.12, 304.395, 323.325, 344.235, 365.625, 399.33, 439.785, 508.44]
]
self.maxReadTime = 3 # 阅读时长不能超过视频时长的3倍
def getIdx(self, percentileList, score):
if score >= percentileList[-1]:
return len(percentileList) - 1
left = 0
right = len(percentileList)
while left <= right:
mid = (left + right) // 2
if percentileList[mid] < score:
left = mid + 1
elif percentileList[mid] > score:
right = mid - 1
else:
return mid
return right
def cdf(self, scores):
result = []
curSum = 0.0
for score in scores:
curSum += score
result.append(curSum)
return result
def laplacePdf(self, bucket, mean, variance=1.0):
return 1.0 / (2.0 * variance) * np.exp(-1.0 * np.abs(np.array(bucket) - np.array(mean)) / variance) + 1e-7
# soft label
def distill(self, timeLabel, labelPercentileList):
probs = self.laplacePdf(labelPercentileList, timeLabel)
probsSum = np.sum(probs)
softLabel = probs / probsSum
return softLabel
# 时长归一化
def encode(self, videoTime, readTime):
if videoTime <= 0 or readTime <= 0:
videoTime = 1e-8
readTime = 1e-8
elif readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
label = self.distill(readTime, timePercentileList)
return label
# 预估时长还原
def decode(self, videoTime, pScore):
if videoTime <= 0:
return 0.0
durationBuk = self.getIdx(self.videoDurationTable, videoTime)
timePercentileList = self.timePercentileTable[durationBuk]
cdfResult = self.cdf(pScore)
readTime = timePercentileList[0]
for i in range(1, len(timePercentileList)):
readTime += (timePercentileList[i] - timePercentileList[i-1]) * (1 - cdfResult[i-1])
if readTime > self.maxReadTime * videoTime:
readTime = self.maxReadTime * videoTime
return readTime
# 测试
timeTrans = TimeTrans()
videoTime = 16
readTime = 8
timeLabel = timeTrans.encode(videoTime, readTime)
print(timeLabel)
readTimeRevocery = timeTrans.decode(videoTime, timeLabel)
print(readTimeRevocery)
参考
- [1][Recommending What Video to Watch Next: A Multitask Ranking
System](https://dl.acm.org/doi/10.1145/3298689.3346997)
- [2][CREAD: A Classification-Restoration Framework with Error
Adaptive Discretization for Watch Time Prediction in Video Recommender
Systems](http://arxiv.org/abs/2401.07521)
- [3][Squared Earth Mover’s Distance-based Loss for Training Deep Neural Networks](http://arxiv.org/abs/1611.05916)