作者 formath 2023-07-07
DeepSpeed-Chat全流程训练实战
背景
ChatGPT出现后,已经有许多开源项目尝试复现其效果,包括LLaMa、DeepSpeed-Chat、ColossalChat、ChatGLM等。其中DeepSpeed-Chat是微软Deep Speed团队的开源项目,其完整的提供了Supervised Fine-tuning、Reward Model Training、RLHF PPO Traing三阶段的代码,逻辑简单,模块划分清晰,另外也由于Deep Speed在大模型训练中的使用非常普遍,所以笔者近期正在研究DeepSpeed-Chat的代码。本文介绍下在13b模型上运行SFT、RW、RLHF全部三阶段的实战情况。
运行条件准备
运行环境
OS: CentOS 7 |
安装依赖: pip install datasets
pip install sentencepiece
pip install protobuf
pip install accelerate
pip install torch
# pip最新版0.9.5有bug,所以用源码安装
git clone https://github.com/microsoft/DeepSpeed.git
cd DeepSpeed
pip install -e .
# pip最新包可能不支持某些模型,所以用源码安装
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
数据和模型
由于公司内GPU集群的机器不允许连接外网,因此先在本地将模型和数据准备好后再传到GPU机器。
参考文档:transformers
offline mode。
开启VPN,按下面代码从Huggingface下载对应模型、词典和数据,完成后将model_output_dir和dataset_output_dir目录传到GPU机器。
模型下载
如果AutoModel.from_pretrained(model_name)内存不足,可以直接从下载缓存cache_dir/model_name/snapshot目录拉取模型。cache_dir的具体配置可以参考transformers
cache。
下载大模型,用于训练SFT Model。 from transformers import AutoModel, AutoTokenizer
model_name = 'facebook/opt-13b' # change this to the model you need
model_output_dir = 'your_dir/facebook_opt_13b'
model = AutoModel.from_pretrained(model_name)
model.save_pretrained(model_output_dir)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained(model_output_dir)
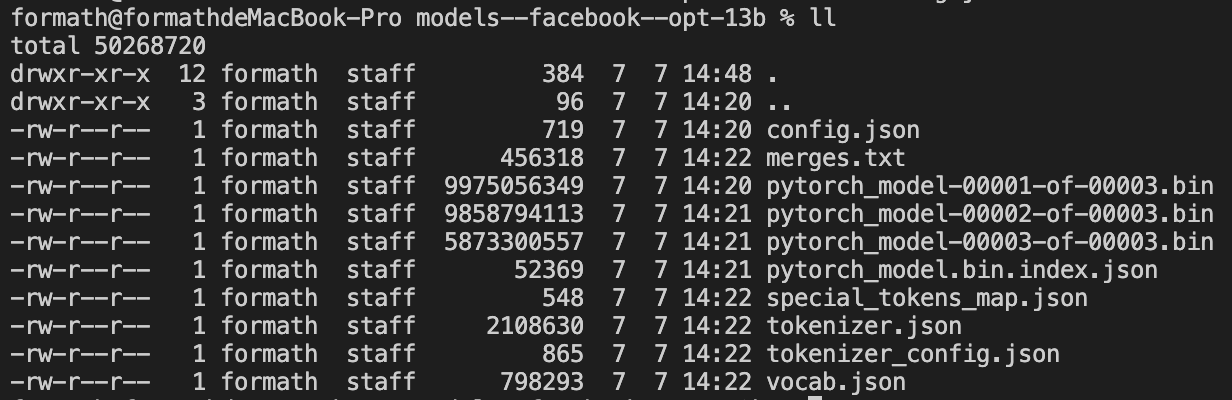
其中config.json为模型配置,内容为: {
"_name_or_path": "facebook/opt-13b",
"_remove_final_layer_norm": false,
"activation_dropout": 0.0,
"activation_function": "relu",
"architectures": [
"OPTForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 2,
"do_layer_norm_before": true,
"dropout": 0.1,
"eos_token_id": 2,
"ffn_dim": 20480,
"hidden_size": 5120,
"init_std": 0.02,
"layerdrop": 0.0,
"max_position_embeddings": 2048,
"model_type": "opt",
"num_attention_heads": 40,
"num_hidden_layers": 40,
"output_projection": true,
"pad_token_id": 1,
"prefix": "</s>",
"torch_dtype": "float16",
"transformers_version": "4.21.0.dev0",
"use_cache": true,
"vocab_size": 50272,
"word_embed_proj_dim": 5120
}
下载小规模模型,用于训练Reward Model。 from transformers import AutoModel, AutoTokenizer
model_name = 'facebook/opt-350m' # change this to the model you need
model_output_dir = 'your_dir/facebook_opt_350m'
model = AutoModel.from_pretrained(model_name)
model.save_pretrained(model_output_dir)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained(model_output_dir)
数据下载
以Dahoas/rm-static数据为例,可自行下载其他数据。
import datasets
dataset_name = 'Dahoas/rm-static' # change this to the dataset you need
dataset_output_dir = 'your_dir/dahoas_rm_static'
dataset = datasets.load_dataset(dataset_name)
dataset.save_to_disk(dataset_output_dir)
Step 1: SFT训练
tokenizer
因为不能联网,所以改成强制使用本地文件,修改以下代码。
DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils/utils.py:
def load_hf_tokenizer(model_name_or_path, fast_tokenizer=True):
#if os.path.exists(model_name_or_path):
# # Locally tokenizer loading has some issue, so we need to force download
# model_json = os.path.join(model_name_or_path, "config.json")
# if os.path.exists(model_json):
# model_json_file = json.load(open(model_json))
# model_name = model_json_file["_name_or_path"]
# tokenizer = AutoTokenizer.from_pretrained(model_name,
# fast_tokenizer=True)
#else:
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, fast_tokenizer=True)
return tokenizer
DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/main.py:
#tokenizer = load_hf_tokenizer(args.model_name_or_path, fast_tokenizer=True)
tokenizer = load_hf_tokenizer('your_dir/facebook_opt_13b', fast_tokenizer=True)
训练数据读取
训练数据也使用缓存,修改文件DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils/data/raw_datasets.py:
class PromptRawDataset(object):
def __init__(self, output_path, seed, local_rank, dataset_name):
self.output_path = output_path
self.seed = seed
self.local_rank = local_rank
if not dataset_name == 'local/jsonfile':
#self.raw_datasets = load_dataset(dataset_name) # 即使dataset_name是本地目录,也会先联网,可以设置export HF_DATASETS_OFFLINE=1或换用load_from_disk
self.raw_datasets = datasets.load_from_disk(dataset_name)
任务启动脚本
修改文件DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/training_scripts/single_node/run_13b.sh:
deepspeed main.py \
--data_path your_dir/dahoas_rm_static \
--data_split 2,4,4 \
--model_name_or_path your_dir/facebook_opt_13b \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--max_seq_len 512 \
--learning_rate 1e-4 \
--weight_decay 0. \
--num_train_epochs 16 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--gradient_checkpointing \
--zero_stage $ZERO_STAGE \
--lora_dim 128 \
--lora_module_name decoder.layers. \
--deepspeed \
--output_dir $OUTPUT \
&> $OUTPUT/training.log
启动训练
cd DeepSpeedExamples/applications/DeepSpeed-Chat |
没问题的话就可以在DeepSpeed-Chat/output/actor-models/13b/training.log看到训练情况了:
229 ***** Running training *****
230 ***** Evaluating perplexity, Epoch 0/16 *****
231 ppl: 2771.550537109375
232 Beginning of Epoch 1/16, Total Micro Batches 3813
233 [2023-07-07 15:34:07,295] [INFO] [loss_scaler.py:188:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
234 Invalidate trace cache @ step 0: expected module 13, but got module 0
235 [2023-07-07 15:34:08,960] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
236 [2023-07-07 15:34:10,421] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 32768, reducing to 16384
237 [2023-07-07 15:34:12,200] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 16384, reducing to 8192
238 [2023-07-07 15:34:13,468] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 8192, reducing to 4096
239 [2023-07-07 15:34:14,738] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4096, reducing to 2048
240 [2023-07-07 15:34:17,337] [INFO] [loss_scaler.py:181:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2048, reducing to 1024
241 [2023-07-07 15:34:19,964] [INFO] [logging.py:96:log_dist] [Rank 0] step=10, skipped=7, lr=[9.999999940336507e-05, 9.999999940336507e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
242 [2023-07-07 15:34:19,964] [INFO] [timer.py:199:stop] epoch=0/micro_step=10/global_step=10, RunningAvgSamplesPerSec=2.9106454245373556, CurrSamplesPerSec=3.07555254100577, MemAllocat ed=36.12GB, MaxMemAllocated=40.26GB
243 [2023-07-07 15:34:32,952] [INFO] [logging.py:96:log_dist] [Rank 0] step=20, skipped=7, lr=[9.999998879652199e-05, 9.999998879652199e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
244 [2023-07-07 15:34:32,952] [INFO] [timer.py:199:stop] epoch=0/micro_step=20/global_step=20, RunningAvgSamplesPerSec=3.003776798900565, CurrSamplesPerSec=3.0893153637186064, MemAlloca ted=36.12GB, MaxMemAllocated=40.26GB
245 [2023-07-07 15:34:45,914] [INFO] [logging.py:96:log_dist] [Rank 0] step=30, skipped=7, lr=[9.99999649311278e-05, 9.99999649311278e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
246 [2023-07-07 15:34:45,914] [INFO] [timer.py:199:stop] epoch=0/micro_step=30/global_step=30, RunningAvgSamplesPerSec=3.0336418997022405, CurrSamplesPerSec=3.0865395529882864, MemAlloc ated=36.12GB, MaxMemAllocated=40.26GB
247 [2023-07-07 15:34:58,905] [INFO] [logging.py:96:log_dist] [Rank 0] step=40, skipped=7, lr=[9.999992780718883e-05, 9.999992780718883e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
248 [2023-07-07 15:34:58,906] [INFO] [timer.py:199:stop] epoch=0/micro_step=40/global_step=40, RunningAvgSamplesPerSec=3.0462048161750825, CurrSamplesPerSec=3.0772742271467597, MemAlloc ated=36.12GB, MaxMemAllocated=40.26GB
249 [2023-07-07 15:35:11,897] [INFO] [logging.py:96:log_dist] [Rank 0] step=50, skipped=7, lr=[9.999987742471495e-05, 9.999987742471495e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
250 [2023-07-07 15:35:11,898] [INFO] [timer.py:199:stop] epoch=0/micro_step=50/global_step=50, RunningAvgSamplesPerSec=3.0535265510887886, CurrSamplesPerSec=3.0858537581286103, MemAlloc ated=36.12GB, MaxMemAllocated=40.26GB
251 [2023-07-07 15:35:24,885] [INFO] [logging.py:96:log_dist] [Rank 0] step=60, skipped=7, lr=[9.999981378371948e-05, 9.999981378371948e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
252 [2023-07-07 15:35:24,886] [INFO] [timer.py:199:stop] epoch=0/micro_step=60/global_step=60, RunningAvgSamplesPerSec=3.058528008594015, CurrSamplesPerSec=3.089157229026472, MemAllocat ed=36.12GB, MaxMemAllocated=40.26GB
253 [2023-07-07 15:35:37,859] [INFO] [logging.py:96:log_dist] [Rank 0] step=70, skipped=7, lr=[9.999973688421931e-05, 9.999973688421931e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
254 [2023-07-07 15:35:37,860] [INFO] [timer.py:199:stop] epoch=0/micro_step=70/global_step=70, RunningAvgSamplesPerSec=3.062547383419453, CurrSamplesPerSec=3.0862085394366274, MemAlloca ted=36.12GB, MaxMemAllocated=40.26GB
255 [2023-07-07 15:35:50,853] [INFO] [logging.py:96:log_dist] [Rank 0] step=80, skipped=7, lr=[9.999964672623485e-05, 9.999964672623485e-05], mom=[(0.9, 0.95), (0.9, 0.95)]
256 [2023-07-07 15:35:50,854] [INFO] [timer.py:199:stop] epoch=0/micro_step=80/global_step=80, RunningAvgSamplesPerSec=3.0649199847585775, CurrSamplesPerSec=3.081825198818058, MemAlloca ted=36.12GB, MaxMemAllocated=40.26GB
每轮评估指标的变化情况如下,可以看到开始几轮效果反而下降,后面几轮又开始提升。
ppl: 2771.550537109375
ppl: 2.4410853385925293
ppl: 2.680394172668457
ppl: 2.779381036758423
ppl: 2.80298113822937
ppl: 2.813119888305664
ppl: 2.8290116786956787
ppl: 2.833710193634033
ppl: 2.832332134246826
ppl: 2.8273046016693115
ppl: 2.8215107917785645
ppl: 2.8162872791290283
ppl: 2.808527946472168
ppl: 2.792924165725708
ppl: 2.775484561920166
ppl: 2.755317449569702
ppl: 2.74511981010437
Step 2: Reward Model训练
tokenizer
DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/main.py:
#tokenizer = load_hf_tokenizer(args.model_name_or_path, fast_tokenizer=True)
tokenizer = load_hf_tokenizer('your_dir/facebook_opt_350m', fast_tokenizer=True)
训练数据读取
训练数据与SFT阶段一样,所以这里没有修改。
任务启动脚本
修改文件DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/training_scripts/single_node/run_350m.sh:
deepspeed main.py \
--data_path your_dir/dahoas_rm_static \
--data_split 2,4,4 \
--model_name_or_path your_dir/facebook_opt_350m \
--num_padding_at_beginning 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--max_seq_len 512 \
--learning_rate 5e-5 \
--weight_decay 0.1 \
--num_train_epochs 1 \
--disable_dropout \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--zero_stage $ZERO_STAGE \
--deepspeed \
--output_dir $OUTPUT \
&> $OUTPUT/training.log
启动训练
cd DeepSpeedExamples/applications/DeepSpeed-Chat |
没问题的话就可以在DeepSpeed-Chat/output/reward-models/350m/training.log看到训练情况了。每轮评估指标的变化情况:
chosen_last_scores (higher is better) : 2.7135448455810547, acc (higher is better) : 0.4949999749660492
chosen_last_scores (higher is better) : -8.86074161529541, acc (higher is better) : 0.5600000023841858
Step 3: RLHF训练
tokenizer
DeepSpeed-Chat代码里actor和critic模型用的是同一个tokenizer,因为opt-13b和opt-350m的词典一样所以只加载一个tokenizer不会报错,如果不一致的话需要修改代码,让它们用各自的tokenizer。
训练数据读取
训练数据与SFT、RW阶段一样,所以这里没有修改。
任务启动脚本
目前DeepSpeed Hybrid
Engine会报以下错,所以先关掉--enable_hybrid_engine。关掉后则会CUDA
out of memory,所以再加上--offload_reference_model。
232 File "/home/formath/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/rlhf_engine.py", line 119, in _init_actor
233 actor_engine, *_ = deepspeed.initialize(model=actor_model,
234 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/__init__.py", line 153, in initialize
235 engine = DeepSpeedHybridEngine(args=args,
236 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 52, in __init__
237 self.create_inference_module()
238 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 359, in create_inference_module
239 self.create_inference_containers(self.module)
240 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 308, in create_inference_containers
241 self.create_inference_containers(child, layer_id=layer_id)
242 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 308, in create_inference_containers
243 self.create_inference_containers(child, layer_id=layer_id)
244 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 308, in create_inference_containers
245 self.create_inference_containers(child, layer_id=layer_id)
246 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 288, in create_inference_containers
247 self._inference_containers.append(self.inference_policies[child.__class__][0](
248 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/hybrid_engine.py", line 107, in new_inference_container
249 _container.set_tensor_parallel_config(self._config.hybrid_engine.inference_tp_size, self.mp_group)
250 File "/conda/envs/py39/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 460, in __getattr__
251 raise AttributeError(f"'{type(self).__name__}' object has no attribute '{name}'")
252 AttributeError: 'DeepSpeedHybridEngine' object has no attribute 'mp_group'
修改文件DeepSpeedExamples/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/training_scripts/single_node/run_13b.sh:
deepspeed --master_port 12346 main.py \
--data_path your_dir/dahoas_rm_static \
--data_split 2,4,4 \
--actor_model_name_or_path $ACTOR_MODEL_PATH \
--critic_model_name_or_path $CRITIC_MODEL_PATH \
--num_padding_at_beginning 1 \
--per_device_train_batch_size 16 \
--per_device_mini_train_batch_size 16 \
--generation_batch_numbers 1 \
--ppo_epochs 1 \
--max_answer_seq_len 256 \
--max_prompt_seq_len 256 \
--actor_learning_rate ${Actor_Lr} \
--critic_learning_rate ${Critic_Lr} \
--num_train_epochs 1 \
--lr_scheduler_type cosine \
--gradient_accumulation_steps 1 \
--num_warmup_steps 100 \
--deepspeed --seed 1234 \
--offload_reference_model \
--inference_tp_size 2 \
--actor_zero_stage $ACTOR_ZERO_STAGE \
--critic_zero_stage $CRITIC_ZERO_STAGE \
--actor_gradient_checkpointing \
--disable_actor_dropout \
--actor_lora_dim 128 \
--actor_lora_module_name decoder.layers. \
--output_dir $OUTPUT \
&> $OUTPUT/training.log
启动训练
cd DeepSpeedExamples/applications/DeepSpeed-Chat |
没问题的话就可以在DeepSpeed-Chat/step3-models/13b/training.log看到训练情况了。
723 ***** Running training *****
724 Beginning of Epoch 1/1, Total Generation Batches 1907
725 [2023-07-12 14:56:26,391] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
726 [2023-07-12 14:56:26,872] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
727 epoch: 0|step: 0|ppo_ep: 1|act_loss: -0.341552734375|cri_loss: 0.1712646484375|unsuper_loss: 0.0
728 average reward score: -7.6640625
729 -------------------------------------------------------------------------------------
730 [2023-07-12 14:57:59,326] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
731 [2023-07-12 14:58:00,227] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
732 epoch: 0|step: 1|ppo_ep: 1|act_loss: -0.386474609375|cri_loss: 0.19775390625|unsuper_loss: 0.0
733 average reward score: -7.78125
734 -------------------------------------------------------------------------------------
735 [2023-07-12 14:59:19,445] [WARNING] [stage3.py:1898:step] 5 pytorch allocator cache flushes since last step. this happens when there is high memory pressure and is detrimental to pe rformance. if this is happening frequently consider adjusting settings to reduce memory consumption. If you are unable to make the cache flushes go away consider adding get_accelera tor().empty_cache() calls in your training loop to ensure that all ranks flush their caches at the same time
736 [2023-07-12 14:59:19,709] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 32768, reducing to 16384
737 epoch: 0|step: 2|ppo_ep: 1|act_loss: -0.35400390625|cri_loss: 0.1790771484375|unsuper_loss: 0.0
738 average reward score: -7.640625
739 -------------------------------------------------------------------------------------
740 [2023-07-12 15:00:39,293] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 16384, reducing to 8192
741 epoch: 0|step: 3|ppo_ep: 1|act_loss: -0.31884765625|cri_loss: 0.1573486328125|unsuper_loss: 0.0
742 average reward score: -7.61328125
743 -------------------------------------------------------------------------------------
744 [2023-07-12 15:01:58,839] [WARNING] [stage3.py:1898:step] 5 pytorch allocator cache flushes since last step. this happens when there is high memory pressure and is detrimental to pe rformance. if this is happening frequently consider adjusting settings to reduce memory consumption. If you are unable to make the cache flushes go away consider adding get_accelera tor().empty_cache() calls in your training loop to ensure that all ranks flush their caches at the same time
745 epoch: 0|step: 4|ppo_ep: 1|act_loss: -0.36962890625|cri_loss: 0.18896484375|unsuper_loss: 0.0
746 average reward score: -7.78125
747 -------------------------------------------------------------------------------------
748 epoch: 0|step: 5|ppo_ep: 1|act_loss: -0.32373046875|cri_loss: 0.1724853515625|unsuper_loss: 0.0
749 average reward score: -7.7109375
750 -------------------------------------------------------------------------------------
751 epoch: 0|step: 6|ppo_ep: 1|act_loss: -0.327392578125|cri_loss: 0.415283203125|unsuper_loss: 0.0
752 average reward score: -8.3125
753 -------------------------------------------------------------------------------------
754 epoch: 0|step: 7|ppo_ep: 1|act_loss: -0.368408203125|cri_loss: 0.208740234375|unsuper_loss: 0.0
755 average reward score: -7.84765625
756 -------------------------------------------------------------------------------------
757 epoch: 0|step: 8|ppo_ep: 1|act_loss: -0.340087890625|cri_loss: 0.1898193359375|unsuper_loss: 0.0
758 average reward score: -7.76953125
759 -------------------------------------------------------------------------------------
对话测试
以上训练结束后,就可以导入各阶段的模型进行对话了,比如用step
3保存的模型进行对话。 cd DeepSpeedExamples/applications/DeepSpeed-Chat
python chat.py --path /home/formath/DeepSpeedExamples/applications/DeepSpeed-Chat/output/step3-models/13b/actor --max_new_tokens 512